
書籍転載:TensorFlowはじめました ― 実践!最新Googleマシンラーニング(5)
TensorFlowによる推論 ― 画像を分類するCIFAR-10の基礎
転載5回目。CIFAR-10データセットを使った学習と評価を行う。画像データの読み込みが終わったので、今回は画像の種類(クラス)を判別、つまり「推論」について説明する。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『TensorFlowはじめました ― 実践!最新Googleマシンラーニング』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『TensorFlowはじめました ― 実践!最新Googleマシンラーニング』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。プログラムのダウンロードは、「TensorFlowはじめました」のサポート用フォームから行えます。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
2.2 推論(inference)
画像データの読み込みができたら、次は画像の種類(クラス)を判別します。これを「推論」と呼びます。
リスト2.3のinference関数は、与えた画像(image_node)が、どのクラスに属するのか推論するグラフを構築します。この推論グラフのことを「モデル」や「ネットワーク」と呼びます。
本書では、推論のモデルとして、多層のCNN (Convolutional Neural Network: 畳み込みニューラルネットワーク)を使います。
|
# coding: UTF-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
NUM_CLASSES = 10
def _get_weights(shape, stddev=1.0):
var = tf.get_variable(
'weights',
shape,
initializer=tf.truncated_normal_initializer(stddev=stddev))
return var
def _get_biases(shape, value=0.0):
var = tf.get_variable(
'biases',
shape,
initializer=tf.constant_initializer(value))
return var
def inference(image_node):
# conv1
with tf.variable_scope('conv1') as scope:
weights = _get_weights(shape=[5, 5, 3, 64], stddev=1e-4)
conv = tf.nn.conv2d(image_node, weights, [1, 1, 1, 1], padding='SAME')
biases = _get_biases([64], value=0.1)
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope.name)
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
# conv2
with tf.variable_scope('conv2') as scope:
weights = _get_weights(shape=[5, 5, 64, 64], stddev=1e-4)
conv = tf.nn.conv2d(pool1, weights, [1, 1, 1, 1], padding='SAME')
biases = _get_biases([64], value=0.1)
bias = tf.nn.bias_add(conv, biases)
conv2 = tf.nn.relu(bias, name=scope.name)
# pool2
pool2 = tf.nn.max_pool(conv2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool2')
reshape = tf.reshape(pool2, [1, -1])
dim = reshape.get_shape()[1].value
# fc3
with tf.variable_scope('fc3') as scope:
weights = _get_weights(shape=[dim, 384], stddev=0.04)
biases = _get_biases([384], value=0.1)
fc3 = tf.nn.relu(
tf.matmul(reshape, weights) + biases,
name=scope.name)
# fc4
with tf.variable_scope('fc4') as scope:
weights = _get_weights(shape=[384, 192], stddev=0.04)
biases = _get_biases([192], value=0.1)
fc4 = tf.nn.relu(tf.matmul(fc3, weights) + biases, name=scope.name)
# output
with tf.variable_scope('output') as scope:
weights = _get_weights(shape=[192, NUM_CLASSES], stddev=1 / 192.0)
biases = _get_biases([NUM_CLASSES], value=0.0)
logits = tf.add(tf.matmul(fc4, weights), biases, name='logits')
return logits
|
inferenceが構築するグラフは、画像データ(image_node)を入力すると、10個のfloat32型の要素を持つリスト(logits)を返します。logitsの値は、それぞれのクラスに対応しており、値が大きいほどそのクラスに近いと推論されたことを表します。
たとえば、リスト2.4の結果はモデルが、入力した画像を「Ship: 8」にもっとも近いと判定したことを意味します。
|
[[ -0.30980146 -1.23266304 -0.43941006 1.43687356 -0.27061576
1.81567788 -0.90203303 -1.03553808 4.27697229 -2.6989603 ]]
|
モデルの構造
ここからは、構築したモデルの構造について説明します。
図2.4は、リスト2.3のモデルを図解したものです。TensorFlowの用意しているCIFAR-10チュートリアルのモデルを簡略化したもので、2つの「畳み込み層」と「プーリング層」、「全結合層」で構成されています。
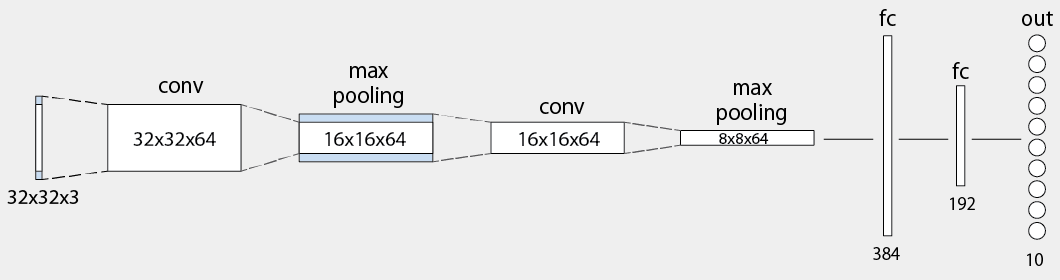
畳み込み層(Convolutional layer)
「畳み込み層」は、画像から特徴量を抽出します。
|
# conv1
with tf.variable_scope('conv1') as scope:
weights = _get_weights(shape=[5, 5, 3, 64], stddev=1e-4)
conv = tf.nn.conv2d(image_node, weights, [1, 1, 1, 1], padding='SAME')
biases = _get_biases([64], value=0.1)
bias = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(bias, name=scope.name)
|
まず画像に対して「畳み込み(tf.nn.conv2d)」を行います。
weightsは「Rank 4」のTensor(多次元配列)です。リスト2.5では[5, 5, 3, 64]を指定しています。これは[5x5]の大きさを持った、3チャンネルのフィルターを64枚、使うことを表しています。
Note: 呼び方の違い
「フィルター(Filter)」を「カーネル(Kernel)*2」または「パッチ(Patch)」と呼ぶこともありますが、どれも同じような意味と考えて良さそうです。
機械学習にはこのように「言い方は違うけれど同じような意味」という単語があります。たとえば「訓練」と「学習」、「損失関数」と「誤差関数」、「Dense Layer」と「Fully-connected Layer」、「中間層」と「隠れ層」は同じような意味で使われているようです。
- *2 後述する「プーリング処理」の引数名はksizeとなっており、カーネルを意識していることがわかります。
次に、tf.nn.bias_addでバイアスを加算します。バイアスは、畳み込みに使ったフィルターの枚数と同じ値を指定します。
■活性化関数
最後に「活性化関数」で各フィルターの特徴量を計算します。リスト2.5では、活性化関数にReLU関数(tf.nn.relu)を使っています。
フィルター(weights)の初期値は、stddevに与える標準偏差の切断正規分布(Truncated Normal Distribution)から生成されます。また、biasesの値はvalueの値で初期化されたTensorです。
Note: 活性化関数
TensorFlowには活性化関数として、ReLU (Rectified Linear Unit)関数tf.nn.reluの他にも、シグモイド関数tf.sigmoidやtanh関数tf.tanhなどが用意*3されています。
プーリング層(Pooling layer)
「プーリング層」は、畳み込み層で抽出した特徴量を圧縮します。この行程を経ることにより、微少な位置変化に対する応答不変性を獲得できると言われています。
|
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
|
リスト2.6では、[3x3]の大きさ、移動量2の条件で最大値プーリング(tf.nn.max_pool)を実行しています。
TensorFlowには、他にも「最小値プーリング(tf.nn.min_pool)」や「平均値プーリング(tf.nn.ave_pool)」が用意されています。
コラム:paddingのSAMEとVALID
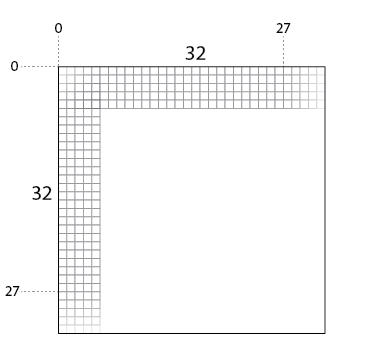
畳み込みやプーリングでは、小さなフィルター(パッチ)をスライドさせて、データ全体をスキャンします。そのため、スライド幅を1とした場合、処理後のサイズは入力するデータより[縦横のサイズ - 1]の分、小さくなります。
例えば、[32x32]の画像を[5x5]のフィルター、スライド幅1で畳み込むと、処理後のサイズは[28x28]になります。
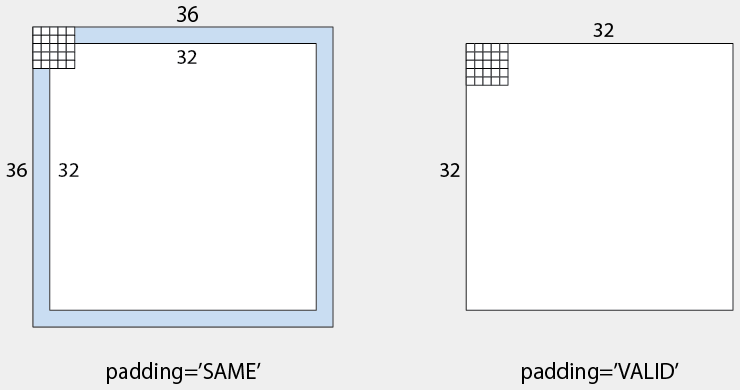
リスト2.5のtf.nn.conv2dや、リスト2.6のtf.nn.max_poolでは、引数に「padding='SAME'」を指定しています。SAMEを指定すると、畳み込みで小さくなる値の分のパディングをあらかじめ付加して処理します。そのため、入力と出力の大きさは同じになります。
パディングをしたくない場合は「padding='VALID'」を指定します。
全結合層(Fully-connected layer)
「全結合層」は、畳み込みとプーリングによって得られたすべての値を結合します。
全結合するTensorは、1次元配列である必要があります。多次元配列を1次元配列に変換することを平坦化(flatten)と呼びます。
リスト2.7では2回目のプーリング層(pool2)の出力をtf.reshapeで平坦化しています*4。
|
reshape = tf.reshape(pool2, [1, -1])
dim = reshape.get_shape()[1].value
# fc3
with tf.variable_scope('fc3') as scope:
weights = _get_weights(shape=[dim, 384], stddev=0.04)
biases = _get_biases([384], value=0.1)
fc3 = tf.nn.relu(
tf.matmul(reshape, weights) + biases,
name=scope.name)
|
平坦化された前層の入力(reshape)にtf.matmulを使って重みを乗算し、その結果にバイアスを加算します。
- *4 実際には完全に平坦化していませんが、これはTensorFlowの畳み込みやプーリングのオペレーションが、複数の画像データを同時に処理する「ミニバッチ学習」を前提に設計されているためです。
出力層(Output Layer)
出力層は、最終的に認識するクラスと同じ数のノードがあります。この計算結果が、それぞれのクラスに対応する「確からしさ」になります。
リスト2.8の場合、定数NUM_CLASSESの値はCIFAR-10のクラス数である10になります。
|
# output
with tf.variable_scope('output') as scope:
weights = _get_weights(shape=[192, NUM_CLASSES], stddev=1 / 192.0)
biases = _get_biases([NUM_CLASSES], value=0.0)
logits = tf.add(tf.matmul(fc4, weights), biases, name='logits')
|
パラメーター
「畳み込み層」と「全結合層」で利用している「重み(weight)」と「バイアス(bias)」を「モデルのパラメーター」と言います。これらの値はグラフ上では変数(Variable)として保持されます。
多層構造のモデルの場合、必要な重みとバイアスの数も多くなります。そのため、リスト2.9のような変数の取得を簡略化するためのヘルパー関数_get_weightsと_get_biasesを用意しています。
|
def _get_weights(shape, stddev=1.0):
var = tf.get_variable(
'weights',
shape,
initializer=tf.truncated_normal_initializer(stddev=stddev))
return var
def _get_biases(shape, value=0.0):
var = tf.get_variable(
'biases',
shape,
initializer=tf.constant_initializer(value))
return var
|
「学習」で変化するのは、これらパラメーターの値です。学習を実行するのは後述する「最適化アルゴリズム」で、モデルそのものは現在のパラメーターを使って推論する役割しか持ちません。
■trainable
筆者がそうだったのですが、データフロープログラミングと機械学習の経験がない人は、なぜこれらのコードで値が変化するのか、理解に苦しむかもしれません。そんな人は、tf.get_variableのAPIを確認してみてください。
|
tf.get_variable(name,
shape=None,
dtype=tf.float32,
initializer=None,
regularizer=None,
trainable=True,
collections=None)
|
変数を取得するオペレーションの引数trainableは、学習のときに値を調整する対象とするかを表します。
後述する最適化アルゴリズムは、セッションからtrainableがTrueの変数(パラメーター)を取り出して、それらの値を更新することで学習を進めるのです。
Note: trainable
逆に言えば、最適化アルゴリズムはtrainableがTrueの変数を勝手に変更してしまいます。そのため、変更されたくない変数を宣言するときは明示的にFalseを指定する必要があります。
推論の実行
構築したグラフの計算が実行されるのは、セッション内でオペレーションを実行した時です。関数inferenceを実行した時点では、logitsの値は計算されません。
リスト2.10は、オペレーションlogitsを実行するプログラムです。学習データ(data_batch_[1-5].bin)に含まれる50,000枚の画像をinferenceで構築するグラフに入力して、それぞれの結果をlogitsとして得ます。
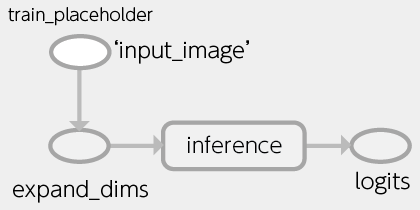
なお、TensorFlowの畳み込みニューラルネットワーク関係のオペレーションは、1つ以上のデータをまとめて処理するように作られています。そこで、プレースホルダーtrain_placeholderで画像データを受け取った後、オペレーションtf.expand_dimsを使って次元を拡張しています。
|
# coding: UTF-8
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
import time
import tensorflow as tf
import model as model
from reader import Cifar10Reader
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_integer('epoch', 30, "訓練するEpoch数")
tf.app.flags.DEFINE_string('data_dir', './data/', "訓練データのディレクトリ")
tf.app.flags.DEFINE_string('checkpoint_dir', './checkpoints/',
"チェックポイントを保存するディレクトリ")
filenames = [
os.path.join(
FLAGS.data_dir,'data_batch_%d.bin' % i) for i in range(1, 6)
]
def main(argv=None):
train_placeholder = tf.placeholder(tf.float32,
shape=[32, 32, 3],
name='input_image')
# (width, height, depth) -> (batch, width, height, depth)
image_node = tf.expand_dims(train_placeholder, 0)
logits = model.inference(image_node)
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
total_duration = 0
for epoch in range(1, FLAGS.epoch + 1):
start_time = time.time()
for file_index in range(5):
print('Epoch %d: %s' % (epoch, filenames[file_index]))
reader = Cifar10Reader(filenames[file_index])
for index in range(10000):
image = reader.read(index)
logits_value = sess.run([logits],
feed_dict={
train_placeholder: image.byte_array,
})
if index % 1000 == 0:
print('[%d]: %r' % (image.label, logits_value))
reader.close()
duration = time.time() - start_time
total_duration += duration
print('epoch %d duration = %d sec' % (epoch, duration))
tf.train.SummaryWriter(FLAGS.checkpoint_dir, sess.graph)
print('Total duration = %d sec' % total_duration)
if __name__ == '__main__':
tf.app.run()
|
プログラムを実行すると、リスト2.11のような結果になります*5。
|
[6]: [[[ 0.00667406, 0.00073374, -0.01612439, -0.00132072, -0.00176617,
0.0075357 , 0.0010216 , 0.01342955, -0.02436399, 0.01280629]]]
[9]: [[[ 0.00667909, 0.00072604, -0.01612369, -0.00134 , -0.00176804,
0.00754533, 0.00100057, 0.01341876, -0.02436198, 0.01283565]]]
[7]: [[[ 0.0067015 , 0.00074749, -0.01609738, -0.00131153, -0.00179062,
0.00751761, 0.00104108, 0.0134209 , -0.0243591 , 0.01283403]]]
|
- *5 重み(weights)の初期値がランダムで決定されるため、常に同じ結果にはなりません。
正解のラベルに依らず、すべての画像について低い値を示しています。
なぜこういうことが起きるのでしょうか。
それは、現在のプログラムに「学習(learn)」が含まれていないためです。
■
今回は「推論」(=画像の種類・クラスを判別)を行いました。次回は、「学習」(=訓練)について説明します。
※以下では、本稿の前後を合わせて5回分(第3回~第7回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
3. TensorFlowの“テンソル(Tensor)”とは? TensorBoardの使い方
転載3回目。テンソル(Tensor)とTensorBoardによるグラフの可視化を解説する。「第1章 TensorFlowの基礎」は今回で完結。
4. TensorFlowでデータの読み込み ― 画像を分類するCIFAR-10の基礎
転載4回目。今回から「畳み込みニューラルネットワーク」のモデルを構築して、CIFAR-10のデータセットを使った学習と評価を行う。今回はデータの読み込みを説明。
5. 【現在、表示中】≫ TensorFlowによる推論 ― 画像を分類するCIFAR-10の基礎
転載5回目。CIFAR-10データセットを使った学習と評価を行う。画像データの読み込みが終わったので、今回は画像の種類(クラス)を判別、つまり「推論」について説明する。
6. TensorFlowによる学習 ― 画像を分類するCIFAR-10の基礎
転載6回目。CIFAR-10データセットを使った学習と評価を行う。「推論」(=画像の種類・クラスを判別)が終わったので、今回は「学習」(=訓練)について説明する。
7. TensorFlowによる評価 ― 画像を分類するCIFAR-10の基礎
転載7回目(最終回)。CIFAR-10データセットを使った学習と評価を行う。「学習」(=訓練)が終わったので、今回は「評価」について説明する。「第2章 CIFAR-10の学習と評価」は今回で完結。