
書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(4)
マイクロプロセッサからGPU/FPGAの利用へ ― 機械学習ハードウェア実装に関する時代変遷
計算機システムのハードウェア実装では、従来の主要要素であるマイクロプロセッサの性能向上が停滞してきたことから、GPUやFPGAが採用されるように時代が変遷してきた。その内容について概説する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「第1章 イントロダクション、1.4 機械学習の位置づけ」を転載しました。今回は、「第2章 従来のアーキテクチャ、2.1 ハードウェア実装の現実」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
第2章 従来のアーキテクチャ
第2章は従来の計算機システムの主要要素であるマイクロプロセッサの現状、GPUやFPGAの計算機への導入を説明し、1980年代から現在までの計算機システムの変化を俯瞰する。まずマイクロプロセッサ、GPUやFPGAの導入までを説明し、次にアプリケーションの直接解法であるASIC実装を取り上げる。最後は以上の事柄を時間軸上でのアプリケーションの変化に対応して計算機システムが如何に変化したかについて俯瞰する。なお、マイクロプロセッサ、GPU、FPGAの各アーキテクチャの詳細は第4章で取り上げている。
初めに従来の計算機の限界について実際に演算を実行するマイクロプロセッサを例に、性能の停滞からGPUやFPGAが採用されるようになった切っ掛けを紹介する。次に特定のアプリケーションに特化した回路を集積する方法である ASIC(Application-Specific Integrated Circuit)を取り上げる。アプリケーションを実装する際にソフトウェア・プログラムとして実装するのが一般であるので、その視点からそのプログラムあるいはアルゴリズムの持つ特性である、局所性と依存性を紹介する。この特性をより良く利用・応用することで性能やエネルギー効率を向上させることができるので非常に重要な要素である。また、論理回路として実装する際の制約である、配線遅延、エネルギー効率、チップ上に実装可能なリソース量制約等も取り上げる。最後にハードウェア実装のこれまでの歴史を振り返り、80年代から現在まで何が起きてきたのかを説明する。計算機アーキテクチャの行き詰まりと深層学習という新しいアプリケーションの登場により、機械学習ハードウェアの研究が興り始めた事を取り上げる。
2.1 ハードウェア実装の現実
2.1.1 マイクロプロセッサ性能の停滞
従来の計算機アーキテクチャ、特にマイクロプロセッサアーキテクチャはムーアの法則(半導体技術の向上に伴い、1.8年毎にダイに実装されるトランジスタ数が2倍になると予見した【53】。図2.1参照)を前提に単位面積あたり実装できる論理回路の規模がスケールでき、結果としてトランジスタのゲート長が短くなるので動作時のクロックサイクル時間を縮小できて、要求される実行性能(実行に要する時間の短さ)もそれと共にスケールができていた(設計空間という)。
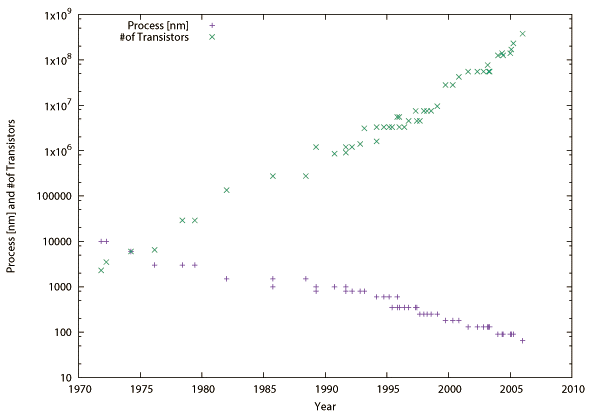
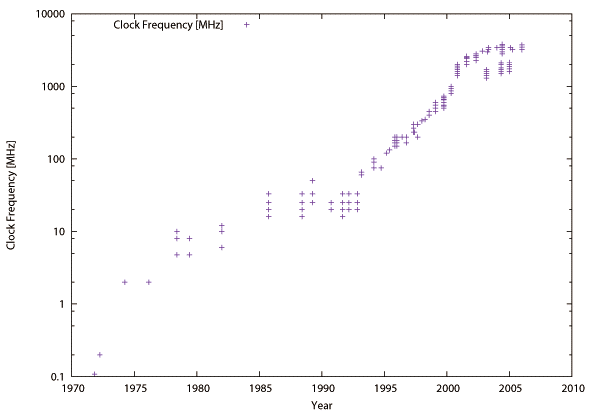
しかし、90年台中盤に入ると設計空間が十分にあっても性能が伸び悩むようになった。主な原因は半導体プロセスの縮小率に対してゲート長の縮小が難しくクロック周波数が向上しづらい事、エネルギー効率の悪化(後述)、そして設計の複雑化である。回路の複雑さはその回路上の最長経路の遅延時間(critical-path delayという)から測ることができる。複数の回路で構成されたパイプライン上、最も長い遅延時間を持つ回路が同期式回路のクロックサイクル時間、つまりクロック周波数(クロックサイクル時間の逆数)を決める。図2.2にパイプライン型プロセッサの各パイプラインステージにおける最長経路遅延時間をオーダ換算で示す。
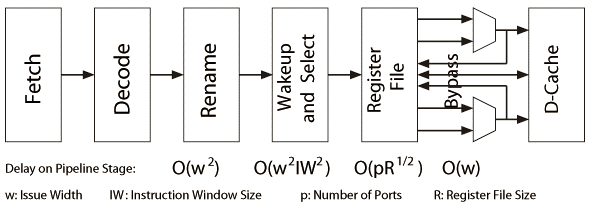
複数命令を同時発行可能なスーパースカラプロセッサは、コンパイラが生成した命令列を動的に解析し、プログラムを破壊しない範囲で実行可能な複数の命令を同時に実行していく。スーパースカラプロセッサで複数の命令を同時に実行するための制御回路の最長経路遅延時間は命令の発行帯域幅(w)の二乗と、命令間の依存性(後述)を破壊しないように同時実行可能な命令を複数検出・選択する命令ウィンドウ*2中に保持できる命令数(IW)の二乗の積に比例する【56】。命令発行帯域幅(w)が広ければ同時発行できる(同時実行可能な最大)命令数(IPC; Instructions Per Cycle)は向上し、命令ウィンドウサイズ(IW)が大きいほど依存性(データおよび制御の依存性は2.2.1で後述している)を解析できる範囲が広がるので、先に発行済みの命令群に対して依存性のない命令を見つけやすくなり、IPCが向上する。
一時利用するデータを複数保持するレジスタファイルの最長経路遅延時間はレジスタ数(R)の平方根と入力ポート数(p)の積に比例する【57】(図2.2参照)。レジスタファイルの持つレジスタ数(R)と同時アクセス可能なポート数(p)が多いほどレジスタリネーミングという手法で命令間のデータ依存性を解決でき(命令中で利用されているレジスタ番号を命令間の真のデータ依存性を破壊しない範囲で動的に変更して命令間の依存性を解消する)、IPCの向上が見込める【58】。
パイプライン型プロセッサの場合、コンパイラが生成した命令列中にある分岐命令も性能を決めている。分岐命令はソフトウェア・プログラムの持つアルゴリズムを形成する上で、制御の流れ(制御フローという)を変えるための命令であり、制御フローの分岐(分岐先命令がある、命令メモリのアドレス)を決める。一般に先行して実行している分岐条件計算の結果を基に分岐先(BTA; Branch Target Address)を決めるので、分岐先の決定はこの先行実行している命令の計算結果に依存する。パイプライン型プロセッサでは、分岐命令の発行は先行実行している分岐条件を決める命令の結果を待つ必要があり、結果が判るまで分岐命令を発行できないのでIPCは最大値よりかなり低くなる。そこで、一般的なマイクロプロセッサは分岐先を予測(Branch Predication、分岐予測という)し、それに基づいて投機的に命令を発行・実行(Speculative Execution、投機的実行という)する手法を利用して、結果を待たずに命令を発行・実行している。分岐予測で保持できる命令メモリのアドレス数が多いほど予測対象が増え、その分投機的実行が可能になる。また、予測精度を上げるために制御フローの解析範囲を広げ、かつ局所予測と広域予測の組み合わせで制御フロー上の各分岐予測精度を向上させている【59】。分岐予測ミス時は投機実行のリカバリを行うためのペナルティー(一般に複数サイクルを要するオーバーヘッドである)を伴う。このペナルティーは一般に発行ステージから分岐条件を決定するステージまでのパイプラインステージ数で決まる。パイプラインを細分化したスーパーパイプライン型プロセッサはこのステージ数が多くなり易い。従って、パイプラインステージ数を多くする場合、それに伴って分岐予測ペナルティーが大きくなるので、より予測精度の高い分岐予測回路が求められる。
以上のIPC向上のための回路は、その複雑化によりスケールメリットを提供できなくなっている。結果として現在のマイクロプロセッサは単一プログラムの実行性能の向上が鈍化している。さらに、複数のプロセッサコア(マイクロプロセッサとキャッシュメモリ等で構成される回路の単位をコアと呼ぶ)で構成されたメニーコアへ発展したが、現在はさらにGPUやFPGAの計算機システムへの導入に進展している。
2.1.2 GPUの計算機システムへの利用
GPU以前のグラフィックス処理回路は、最初から固定設計されたグラフィックス処理専用の回路だった。90年代当初は二次元画像処理用の回路であったが、マルチメディアアプリケーションの登場とともに三次元グラフィックス処理や精細なグラフィックス描画への要求が強くなった。グラフィックス専用回路へプログラミング性が導入されたことにより、グラフィックス・プログラミングが進展し、グラフィックス専用回路の利用者が自分のグラフィックス・アルゴリズムを実装できるようになり、固定されたグラフィックス・パイプライン回路からプログラム可能なグラフィックス処理プロセッサ(Graphics Processing Unit)へと発展したのである【60】。
ポリゴン系グラフィックス処理は、頂点座標データと最低3頂点で構成される面のマップデータで構成され、データが膨大である。しかし各ピクセル単位での処理は同じであり、三次元グラフィックスを二次元画面上にマッピングする過程まで同じ処理を繰り返しているので、データレベル並列性(DLP; Data-Level Parallelism)を得られやすい。このGPUの持つDLP特性を一般的な他のDLP特性を持つアプリケーションへ利用しようと試みる動きが現れ【61】、今日の汎用処理用グラフィックス処理ユニット(GPGPU; General-Purpose GPU)や GPU Computing【60】と呼ばれる汎用処理へのGPU利用が進んだ経緯がある。この流れで、HPC(High-Performance Computing)用として利用が進んでおり、GPUへの倍精度浮動小数点演算の実装によりHPC開発ではGPUの採用が一般化している。
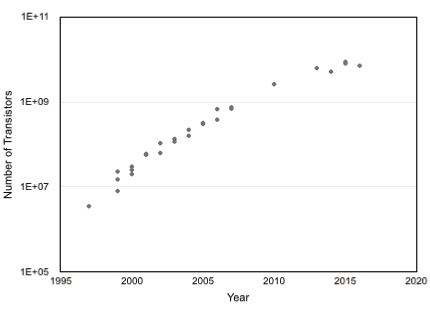
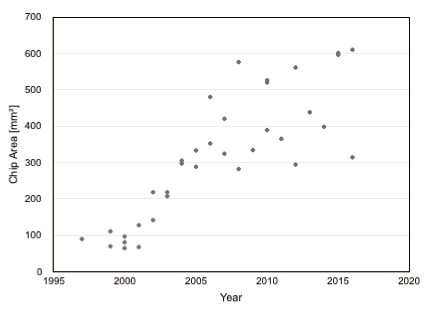
図2.3はGPUの実装傾向を示す。トランジスタ数は2010年頃まで対数スケールで上昇しているがその後の増加ペースは若干落ちている。そのトランジスタ数を実装するためのチップ面積は 600mm2を超えている。チップ面積が600mm2は大体24mm角チップであり、一般的な10mm角チップサイズを大きく上回り、エンタープライズ用メニーコアプロセッサと同等のサイズまで大きくなっている。なお、GPUのアーキテクチャに関しては第4章で説明する。
2.1.3 FPGAの計算機システムへの利用
他方、LSI製造前の動作検証目的で発明されたFPGA(Field-Programmable Gate Array)デバイスは近年最終製品へ利用され始めている。FPGAは求められる論理回路を自由に構成できるデバイスで、一般にそのデバイスに記憶する構成プログラム(Configuration Data、構成データという)を変更すれば何度でも再構成が可能である。設計から市場投入までの期間(一般にTime-to-marketという)を短縮し【62】、かつ多品種少量生産が主流になっている現在、特定用途向けLSIであるASICのNRE(Non Recurrent Engineering)、実装、そして製造コストが見合わないため、FPGAの最終製品への利用が進んでいる。また、従来は計算機のソフトウェアで行われているバグに対処するためのパッチ(修正プログラム)当てもFPGA上に構成された回路で可能になるので、些細な回路のバグであれば市場投入後に構成データを差し替えることで修正できるメリットもある。
現在のFPGAはメモリブロック、積算器と加算器(FPGAではこの2つの演算器の組み合わせ回路をDSPと呼ぶ)を多数実装して、単一チップでのシステム(SoC; System-on-Chipという)実装に対応している。メモリブロックは外部メモリへのアクセス回数を減らす効果とアクセス遅延による待ち時間を削減する効果があり、このメモリブロックを大量にチップ上に実装することで、複数データへの同時並行アクセスを可能にし、低遅延なデータの並列処理による高性能化を実現している。また、DSPの実装により、デジタル信号処理(DSP; Digital Signal Processing)でよく利用される整数積算と整数加算をクロック周波数の低下を抑えた上で効率的に処理できるようにしている。現在のDSPは整数演算と固定少数点演算以外に単精度浮動小数点演算に対応できる回路構成になっており用途が広がっている【63】。
FPGAは汎用デバイスであるため、ASICによる実装と比較してトランジスタ数換算値(ゲート相当数という)、クロック周波数、そして消費電力それぞれの能力が低い(表2.1参照)。ベンチマーク回路ではゲート相当数、クロック周波数、消費電力がそれぞれ3〜4世代程度古いASICに相当するが、メモリブロックやDSPの実装が設計空間の古さを軽減している。設計空間が古くても多くの場面で利用されるのは、ASICはNRE、実装、そして製造コストが多品種少量生産の場合に相対的に高い事と、製造後に修正ができないリスクを回避できるためで、FPGAの最終製品への利用が進んでいる。
| 比較ポイント | Logic Only | Logic and Mem | Logic and DSP | Logic, DSP, Mem |
|---|---|---|---|---|
| Area | 32 | 32 | 24 | 17 |
| Critical-path Delay | 3.4 | 3.5 | 3.5 | 3.0 |
| Dynamic Power Consumption | 14 | 14 | 12 | 7.1 |
近年HPC(High-Performance Computing)システムへのFPGAの導入が進んでいる。2015年12月、Intel社はFPGAデバイスメーカーのAltera社の買収を発表し【64】、FPGAを主要な技術として今後使用してエンタープライズ系のマイクロプロセッサと統合する事を表明している【65】。
■
次回は、「第2章 従来のアーキテクチャ、2.2 特定用途向け集積回路(ASIC)」を転載します。
【参考文献】
- 【52】 Shigeyuki Takano. Performance Scalability of Adaptive Processor Architecture. ACM Transactions on Reconfigurable Technology and Systems (TRETS), April 2017.
- 【53】 G. E. Moore. Cramming More Components Onto Integrated Circuits. Proceedings of the IEEE, 86(1):82-85, January 1998.
- 【54】 R. M. Tomasulo. An Efficient Algorithm for Exploiting Multiple Arithmetic Units. IBM Journal of Research and Development, 11(1):25-33, January 1967.
- 【55】 Shlomo Weiss and James E. Smith. Instruction Issue Logic for Pipelined Supercomputers. SIGARCH Comput. Archit. News, 12(3):110-118, January 1984.
- 【56】 S. Palacharla, N. P. Jouppi, and J. E. Smith. Complexity-Effective Superscalar Processors. In Computer Architecture, 1997. Conference Proceedings. The 24th Annual International Symposium on, pages 206-218, June 1997.
- 【57】 S. Rixner, W. J. Dally, B. Khailany, P. Mattson, U. J. Kapasi, and J. D. Owens. Register organization for media processing. In Computer Architecture, 1997. Conference Proceedings. The 24th Annual International Symposium on, pages 206-218, June 1997.
- 【58】 D. Sima. The design space of register renaming techniques. IEEE Micro, 20(5):70-83, September 2000.
- 【59】 André Seznec, Stephen Felix, Venkata Krishnan, and Yiannakis Sazeides. Design Tradeoffs for the Alpha EV8 Conditional Branch Predictor. In Proceedings of the 29th Annual International Symposium on Computer Architecture, ISCA '02, pages 295-306, Washington, DC, USA, 2002. IEEE Computer Society.
- 【60】(2) J. Nickolls and W. J. Dally. The GPU Computing Era. IEEE Micro, 30(2):56-69, March 2010.
- 【61】 J. Fung and S. Mann. Using multiple graphics cards as a general purpose parallel computer: applications to computer vision. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004., volume 1, pages 805-808161Vol.1, August 2004.
- 【62】 Using Programmable Logic for Gate Array Designs. https://www.altera.co.jp/content/dam/altera-www/global/ja_JP/pdfs/literature/an/archives/an051_01.pdf, January 1996.
- 【63】 Arria 10 Core Fabric and General Purpose I/Os Handbook. https://www.altera.com/content/dam/altera-www/global/en_US/pdfs/literature/hb/arria-10/a10_handbook.pdf, January 2016.
- 【64】 Intel Acquisition of Altera. https://newsroom.intel.com/press-kits/intel-acquisition-of-altera/, December 2015.
- 【65】 Intel Artificial Intelligence: Unleashing the Next Wave. https://newsroom.intel.com/press-kits/intel-artificial-intelligence-unleashing-next-wave/, November 2016.
- 【66】 I. Kuon and J. Rose. Measuring the Gap Between FPGAs and ASICs. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 26(2):203-215, February 2007.
※以下では、本稿の前後を合わせて5回分(第1回~第5回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
1. 機械学習の定義と応用範囲、認知されるキッカケとなった出来事
機械学習はいまなぜ広く認知され注目されているのか。知っておきたい代表的な出来事を紹介。また、機械学習とは何かを定義し、その適用範囲を分類する。
2. 機械学習における学習方法と性能評価の基礎知識
機械学習の基礎知識として、学習用データセットの準備と加工、学習方法(勾配降下法/誤差逆伝播法)やその分類(教師あり学習/教師なし学習/強化学習)、性能評価と検証について概説する。
3. 第4次産業革命とは? 機械学習とブロックチェーンの役割
機械学習の新技術活用は第4次産業革命と呼ばれるが、その意味を説明。さらに、機械学習がデータ処理系であれば手続き処理系に相当するブロックチェーンについても概説する。
4. 【現在、表示中】≫ マイクロプロセッサからGPU/FPGAの利用へ ― 機械学習ハードウェア実装に関する時代変遷
計算機システムのハードウェア実装では、従来の主要要素であるマイクロプロセッサの性能向上が停滞してきたことから、GPUやFPGAが採用されるように時代が変遷してきた。その内容について概説する。
5. 機械学習ハードウェアの基礎知識: 特定用途向け集積回路「ASIC」
特定アプリケーションに特化した回路を集積する方法であるASICについて概説。アプリケーションを表現するアルゴリズムのソフトウェア実装とASIC実装を比較しながらASIC実装の特徴と制約を説明する。