
書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(6)
機械学習のハードウェア化の歴史と、深層学習の登場
1980年代~現在まで、機械学習のハードウェア実装の歴史を振り返る。計算機アーキテクチャの行き詰まりと深層学習の登場により、機械学習ハードウェアの研究が進んできたことを紹介する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「第2章 従来のアーキテクチャ、2.2 特定用途向け集積回路(ASIC)」を転載しました。今回は、「2.3 ハードウェア実装のまとめ」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
2.3 ハードウェア実装のまとめ
2.3.1 計算機産業のこれまで
図2.12は過去35年の計算機産業を振り返っている。大量生産による量産効果でチップや製品の単価は低下し続け、低価格汎用品としてコモディティ化が進んだ。始めは命令レベル並列性(ILP; Instruction-Level Parallelism)といった単一プログラム(単一スレッド)の実行性能が顧客の強い要求であった。90年代はマルチメディアが注目されメディア・アプリケーションに対応する為にデータの高速処理性能が求められ多くのASICが提案された。これに対してプロセッサメーカーはデータレベル並列性(DLP; Data-Level Parallelism)技術の一種であるSIMD(Single Instruction stream and Multiple Data stream)を導入してマイクロプロセッサを拡張し、かつコンパイラをSIMD化に対応させる事でASICを駆逐した。
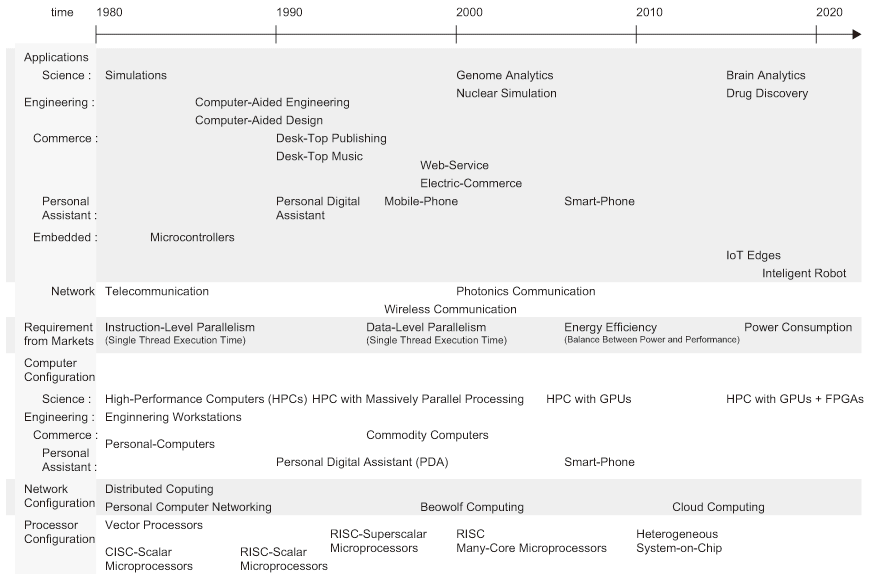
90年代後半以降、外部メモリへのアクセス遅延【73】や回路の複雑化もあり、マイクロプロセッサの実行性能は伸び悩んでいる。2000年以降プロセッサコアを複数搭載し複数スレッドを同時並列に実行させて全体的な性能を向上させる(TLP; Thread-Level Parallelism)メニーコアプロセッサでプロセッサメーカーは顧客に対して訴求した。しかし、実際は多数あるプロセッサコアを効率良く動作させるアプリケーション設計方法やコンパイラ技術はなく複数のコアを活かせていない。
2000年前後から携帯端末の爆発的な普及によりモバイルデバイスがテクノロジドライバになり、性能対消費電力(エネルギー効率)の能力が求められ、様々な最適な回路を混載したSoC(System-on-Chip)実装が進んだ。プロセッサメーカーは顧客への訴求点を依然として実行性能としたため、主要顧客がPC(Personal Computer)からモバイルデバイスに移行したのに対して顧客の要求との間でズレが生じた。つまり要求仕様の予測を誤り、かつMakimoto's Waveで述べた様にアプリケーションの特性に合わせられなくなった事から顧客からの要求に対応できず、他のGPUやFPGAの導入が進むきっかけを作った。データレベル並列性(DLP; Data-Level Parallelism)の特性を持つアプリケーションに対して顧客からの要求があり、GPUが計算機リソースとして利用され始め、さらに最近は高速処理が必要で、かつ相対的に複雑な制御フローを持つアプリケーションに対応する目的でFPGAを計算機リソースとして取り込み始めている。FPGAはアプリケーションをユーザー回路として実装してASIC実装に近い処理性能が得られる事と、逐次更新してサービスインを可能な限り早く行い、その後に修正・更新可能な開発・運用形態が可能である。
近年は主要アプリケーションの変化により顧客要求が高速処理性能から携帯デバイスを意識したエネルギー効率へ変わり、さらに全体としてIoTにおいては消費電力への強い要求へと変貌しようとしている。
2.3.2 機械学習のハードウェア化
従来のマイクロプロセッサを基にした計算機性能の鈍化とASICの高コスト・高リスクの問題から、市場投入期にFPGAとして実装し、ハードウェアバグがある程度解消されて市場で一定のシェアが見込めればASICとして実装する方法が提案されていた【75】【76】【77】。この場合、FPGAとASICの間で論理回路的にも電気的特性でも互換性のある様に設計しておく必要がある。
これに対して、特定利用領域においてその特性に合ったプログラム可能なLSIを収穫期以降まで一貫して提供することで、FPGA以上の高性能・低消費電力・低コストのデバイスを提供する動向がみられる。機械学習システムのハードウェア化もこの流れに沿ったものである。ニューラルネットワーク・ハードウェアはこれまでも研究されてきたが、汎用マイクロプロセッサの急速な進歩によるソフトウェア上のニューラルネットワークに対して性能が及ばなかった事、応用対象範囲が狭かった事などからニューラルネットワーク・ハードウェアが市場に出てもすぐにその活躍機会を失った過去がある【78】。
近年、従来型計算機アーキテクチャは限界を迎え、また情報通信技術の進歩により大量のデータが手に入るようになっており、深層学習に代表される機械学習の研究の進展によって機械学習システムのハードウェア化の研究開発が積極的に行われている。
図2.8は計算機アーキテクチャの研究コミュニティであるISCA(International Symposium on Computer Archi-tecture)とMICRO(International Symposium on Microarchitecture)における各研究分野の発表件数の割合の変化を示す。近年プロセッサコア(図2.8(a)中“CPU”表記の領域)の研究発表件数の割合は小さいがISCAの機械学習ハードウェアを含む特定用途向けアクセラレータ(図2.8(a)中“ACC”表記の領域)とMICROの機械学習ハードウェア(図2.8(b)中“NNH”と表記の領域)関連の発表件数の割合が急激に増加している。
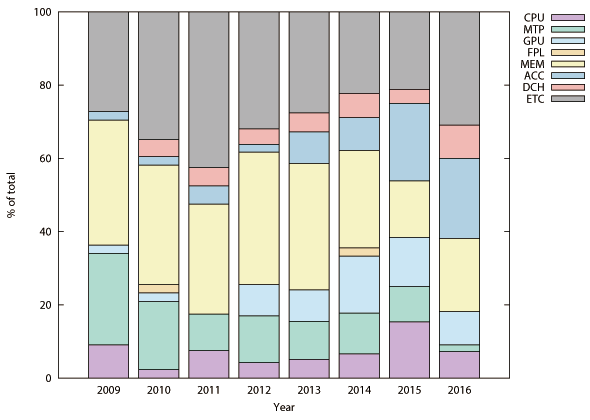
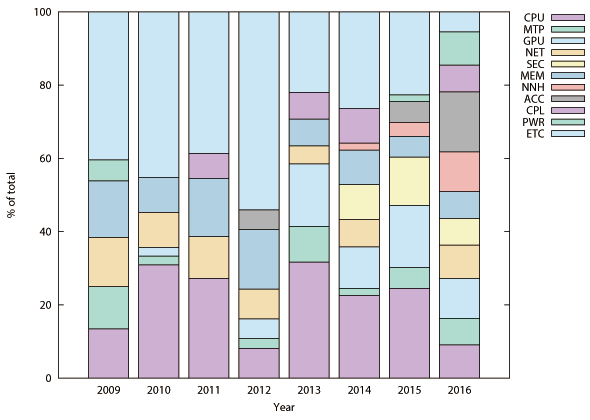
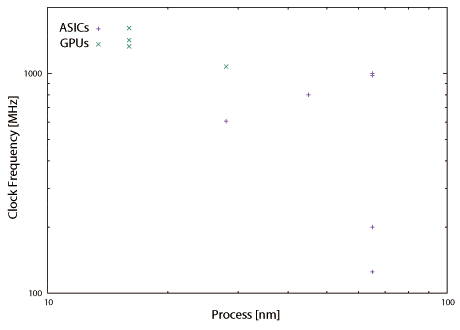
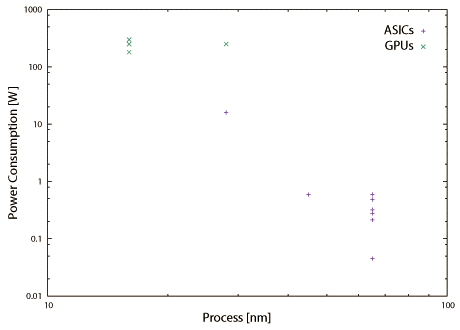
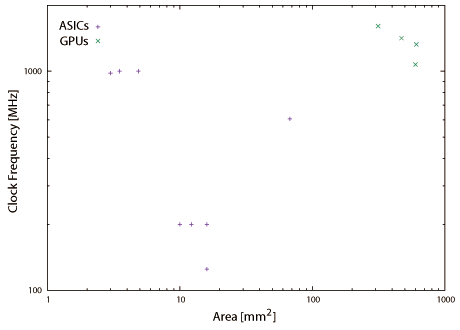
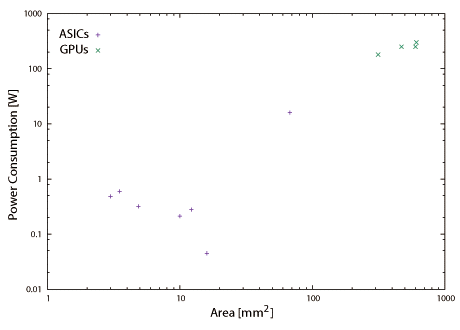
図2.9と図2.10は本書で取り上げている機械学習ハードウェアの動作周波数と消費電力である。一般に利用されているGPUの値もプロットしているが、消費電力はTDP(Thermal Density Power)値である。16nmという最新の半導体プロセスを使用しているGPUのチップ面積は600mm2を超えている。これに対して28nmや主に65nmといった、使い古された半導体プロセスを使用して実装されている機械学習ハードウェア(ASIC実装時)のチップ面積は50mm2程度である。最新の半導体プロセスと大きなチップ面積を要しているGPUはダークシリコン問題と配線遅延時間を考慮して設計されているはずである。その上でクロック周波数が高いという事は各回路間にパイプラインレジスタやメモリユニットを挿入してタイミング調整している事を示唆しており、一つの演算・実行に要するサイクル数は多いので、これを補填するために後述するマルチスレッド技術が必須の状況と推測できる。事例を紹介している第6章でも述べるが(※転載対象外)、GPUのGeForce TITAN Xと比較して機械学習ハードウェア(ASIC実装時)の実行性能(スループット)は数倍から十数倍高い。その上でクロック周波数は低く(半分以下)、消費電力は桁違いに低い(100分の1以下)事からエネルギー効率の面で圧倒的に優位である(数百倍から数千倍)。
2.3.3 ハードウェア化の分類
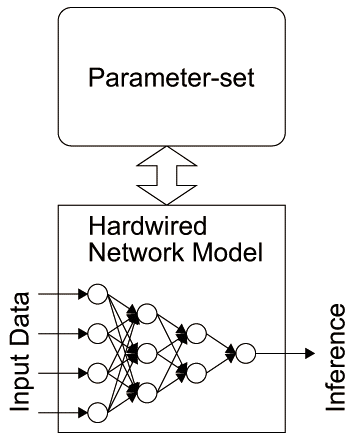
機械学習ハードウェアにはいくつかの種類がある。機械学習モデルをそのまま実装したアクセラレータ(図2.11(a)参照)や、機械学習モデルをプログラムとして実装して、機械学習ハードウェアがそれを実行するモデルもある(図2.11(b)参照)。初期はアクセラレータが主流であったが、最近は完全に固定したハードウェアではなくある程度柔軟性をもたせ、プログラム可能なアクセラレータへと移行している。また、完全にプログラム可能な汎用機械学習ハードウェアも登場している。一般にプログラム可能な機械学習ハードウェアは機械学習プロセッサを謳っていることが多い。メニーコアプロセッサ、GPU、一部のASICでは機械学習プロセッサが研究開発されている。
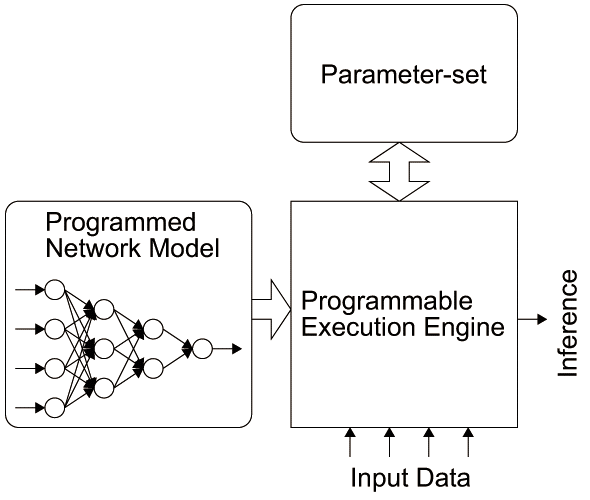
IoTといった組み込み系では、ハードウェアから要求される仕様とネットワークモデルの間に開きがあるので最適化の余地が大きい。IoTは一般に特定用途であり一つのネットワークモデルを実行できれば良いので、アクセラレータ構成への傾向が強い。出荷台数によるが、FPGAで何度も論理回路を書き換えられる特性を利用して、ハードウェアの些細なバグフィックス機能を持たせたり、ハードウェアの更新機能を持たせた製品が主流になると考えられる。
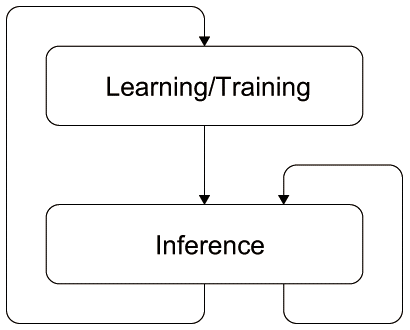
そして、機械学習ハードウェアは学習(Learning)のフェーズと推論(Inference)のフェーズが明確にあり、学習の結果得られる学習の内部情報であるパラメータセット(後述)をハードウェアに出し入れしながら推論や学習を実施する(図2.11(c)参照)。パラメータセットの数が大量にあるため、チップに一般に全て乗らず、チップ外部へのアクセスが必要になる。このメモリアクセスがハードウェアとして性能とエネルギー効率の主な律速の原因になっており、現時点での研究の焦点がここに当たっている。
2.3.4 機械学習ハードウェア化の経緯
付録Aを参照していただきたいが、特に深層学習は行列演算の集合体であり、この行列演算とメモリアクセスの特性に合ったハードウェアが実行時間の短い高性能でかつ高エネルギー効率なハードウェアと言える。
CPUは行列演算の際にその繰り返し演算にループ処理といった無駄な命令の繰り返し実行が必要である。加えて基本的に単純なスカラ演算に特化した演算器しか持っていないので、行列という大量のデータを繰り返し同じ演算を行う処理に向いていない。複雑な制御を行うのにCPUは向いているが、機械学習で相対的にそれほどの複雑な制御は今の所不要である。また、CPUのチップ面積の半分はキャッシュメモリが占めているが局所性を利活用するこのキャッシュメモリのアーキテクチャは深層学習の処理に向いていない不要な部分である。
GPUはもともと座標変換や座標計算向けのハードウェアを起源としており、同じ演算の繰り返しで構成されている行列演算処理に向いている。とはいえ、余分な回路や機能が実装されており無駄が多い。また深層学習におけるニューラルネットワークモデルが必要とするメモリアクセス特性に合ったメモリアクセス制御を持っていない。従って600mm2以上という大規模なチップ面積でかつ1GHz以上という高い動作周波数で実行するため、消費電力は200Wを超えるくらい大量に電力を消費する。このため、演算性能はあるがメモリアクセス特性の不一致と高消費電力によりエネルギー効率はASIC実装と比較して3桁以上低い。
FPGAは1bitという細粒度の計算ノードにより構成されたデバイスであり、ユーザーが望んだ論理回路をその上に構成することができる。問題の直接解法のプラットフォームとして利用されており、アプリケーションをハードウェア実装することに相当する。細粒度の計算ノードであるため、ある程度の幅のあるデータを扱う論理回路を構成する場合、時間軸上でも空間的にもオーバーヘッドが大きくASIC実装と比較すると数世代古い論理回路実装に相当しているのが現状である。従って性能とエネルギー効率の面で、CPUやGPUとASIC実装の中間に位置して中途半端な立ち位置にありこれまでキラーアプリケーションがなかったためその利用が限定的であった。とはいえ、付録Aで述べているが2値表現のニューラルネットワークの研究が進んでおり、その成果次第では今後飛躍する可能性が十分にある。
これらに対してASIC実装はリソース、配線遅延、消費電力、そしてパッケージングといった物理的な制約の下で自由である。専用の論理回路実装もできるし、汎用性を志向した論理回路といったハードウェア設計者が思い描いたアイデアを制約の下でほぼ忠実に実現できる。従って、機械学習モデルの特性に合ったハードウェアを設計し製造すれば、性能とエネルギー効率の両面で最高水準を得られやすい。
■
次回は、「第3章 機械学習と実装方法、3.1 ニューロモルフィックコンピューティング」を転載します。
【参考文献】
- 【73】 Doug Burger, James R. Goodman, and Alain Kägi. Memory Bandwidth Limitations of Future Microprocessors. SIGARCH Comput. Archit. News, 24(2):78-89, May 1996.
- 【75】 Mask-Programmable Logic Devices, June 1996.
- 【76】 Generating Functionally Equivalent FPGAs and ASICs With a Single Set of RTL and Synthesis/Timing Constraints. https://www.altera.com/content/dam/altera-www/global/en_US/pdfs/literature/wp/wp-01095-rtl-synthesis-timing.pdf, February 2009.
- 【77】 Xilinx HardWireTM FpgASIC Overview, 1998.
- 【78】 Oliver Temam. The Rebirth of Neural Networks. In Proceedings of the 37th Annual International Symposium on Computer Architecture, ISCA '10, pages 49-349. IEEE Computer Society, 2010.
※以下では、本稿の前後を合わせて5回分(第4回~第8回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
4. マイクロプロセッサからGPU/FPGAの利用へ ― 機械学習ハードウェア実装に関する時代変遷
計算機システムのハードウェア実装では、従来の主要要素であるマイクロプロセッサの性能向上が停滞してきたことから、GPUやFPGAが採用されるように時代が変遷してきた。その内容について概説する。
5. 機械学習ハードウェアの基礎知識: 特定用途向け集積回路「ASIC」
特定アプリケーションに特化した回路を集積する方法であるASICについて概説。アプリケーションを表現するアルゴリズムのソフトウェア実装とASIC実装を比較しながらASIC実装の特徴と制約を説明する。
6. 【現在、表示中】≫ 機械学習のハードウェア化の歴史と、深層学習の登場
1980年代~現在まで、機械学習のハードウェア実装の歴史を振り返る。計算機アーキテクチャの行き詰まりと深層学習の登場により、機械学習ハードウェアの研究が進んできたことを紹介する。
7. 機械学習のニューロモルフィック・コンピューティング・モデル
機械学習ハードウェアの「ニューロモルフィック・コンピューティング」(前者)と「ニューラル・ネットワーク」という大分類のうち、脳の構造と神経細胞(ニューロン)発火の仕組みを模倣した前者のモデルを説明する。
8. ディープラーニングを含むニューラルネットワーク・モデルと、そのハードウェア実装
一般的なニューラルネットワークモデルとディープラーニング(深層学習)について紹介。さらにそのハードウェアを実装するための一般的な方法を説明する。