
書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(8)
ディープラーニングを含むニューラルネットワーク・モデルと、そのハードウェア実装
一般的なニューラルネットワークモデルとディープラーニング(深層学習)について紹介。さらにそのハードウェアを実装するための一般的な方法を説明する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「第3章 機械学習と実装方法、3.1 ニューロモルフィックコンピューティング」を転載しました。今回は、「3.2 ニューラルネットワーク」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
3.2 ニューラルネットワーク
ニューラルネットワークは脳の機能のみを模倣し統計的手法に基づいたモデルであり、統計的手法が強いモデルでは統計的機械学習という事もある。入力データに重みを積算し、それら全ての総和の値をニューロンの出力を定義している活性化関数へ入力してこのニューロンの出力を得る。ここでは初めに一般的なニューラルネットワークモデルを紹介し、その後にハードウェア実装する一般的方法を説明する。
3.2.1 ニューラルネットワークモデル
入力データに対応する出力層における推論の期待値を教師データあるいはラベルという。ニューラルネットワークではニューロモルフィックコンピューティングで可能なランダムなグラフ構成ではなく、明示的に層構造をとる(図3.3(a))。そして各層への入力データはベクトル、あるいは活性化関数の出力であるためアクティベーションと呼んでいる。複数の入力データをアクティベーション(ベクトル)の要素としてまとめて一つのベクトルとして扱う。シナプスにおける電導率を重みとして表し、その重みを主な要素としたDendriteの情報の集合をパラメータセットといい、その各要素は総称としてパラメータと呼ぶ。また、ニューラルネットワークのトポロジー、パラメータ、活性化関数の組み合わせを称してネットワークモデル、あるいいは単にモデルと呼ぶ。また、このネットワークモデルにおいて、学習の仕組みを含む全体的な構造をアーキテクチャと呼ぶ。
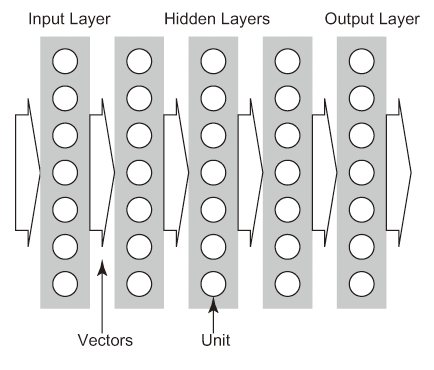
入力層(下位層)から出力層(上位層)へアクティベーションを伝播させるので、順伝播型ニューラルネットワーク(Feedforward Neural Network)や過去のPerceptronモデルの多層化の意味でMulti-Layer Perceptron(MLP)とも呼ばれる。従って、層の数(深さ)で浅いニューラルネットワークと深いニューラルネットワークに分類できる。
- 浅いニューラルネットワーク(Shallow Neural Networks)
入力層と出力層の中間に中間層(隠れ層という)が1層あるモデルを浅いネットワークモデルという。
- Support Vector Machines
Support Vector Machine(SVM【85】)は統計的手法である Logistic regressionモデルなどを包含するネットワークモデルである。Logistic regressionは入力ベクトルの特徴分布*5に境界を引く手法であり、境界により決められた領域内に含まれる入力ベクトルの集合を一つのグループとする境界を表現するパラメータを学習により得るモデルである。運用時のlogistic regressionへの入力ベクトル*6が境界を基準にどの領域に入るかで分類判定する。
これに対しSVMは学習時に最適な境界を探索するのではなく、学習時に学習用入力ベクトルの分布についてグループ分け(インデックスの付与)をしておき、運用時の入力ベクトルが学習で利用した入力ベクトルに一番近い距離にある時、その学習時の入力ベクトルの属するグループと判定する。- *5 ベクトル x ϵ Rn におけるn個の要素のとる値を見る時、このn次元の要素により構成される空間上、その要素の分布を指す。 要素を特徴と呼ぶ事については本章で後述している。
- *6 浅いニューラルネットワークではアクティベーションと呼ばずにベクトルと呼ぶのが一般である。
結果としてlogistic regressionはn次の入力ベクトルに対してn − 1次の境界を決めるが、SVMはn次の境界域を決めることに相当する。例えばn = 2であれば2次元の特徴分布空間中の境界は曲線ではなく、SVMは曲線に幅(余白:マージン)を持たせた領域を学習により得ることに相当する。このようにSVMは余白域を最大化するように学習することから、マージン最大化分類器(Maximum-Margin Classifiers)とも呼ばれる。Logistic regression同様に多分類を含む分類問題といった情報間の構造的相関問題について一般的に広く使用されている。 - Restricted Boltzmann Machines
Boltzmann Machine(BM)は可視ニューロン(visible neuron)と隠れニューロン(hidden neuron)の2種類のユニットからなり、それぞれのユニット群が入力層と隠れ層を構成する【86】。隠れ層は入力層が持つ観測しているデータ(この入力ベクトルを保持する可視ユニットを可視変数という)要素間の相関を表す依存性を検出し、確率分布(Probability Distribution; 確率変数がある値となる確率,又はある集合に属する確率を与える関数【87】)を学習する。
BMはマルコフ確率場(MRF; Markov Random Field)として知られている無向グラフモデルである。MRFを確率変数とした確率分布を表現するGibbs分布を使用して可視変数と隠れ変数の組に対する結合確率分布(Joint Probability Distribution; 変数の組の確率分布)を表現する。そして潜在変数(Latent Variable)を導入することで結合確率分布から可視変数間の依存性を得る。BMの学習はそのモデルの複雑さから設計が難しく実装時に工夫や検証時間を要する。Restricted Boltzmann Machine(RBM)はニューロンに2部グラフ(Bipartite Graph)の制約を持たせ、同じ層内のニューロン間に接続関係がないBMである【88】。Dimensionality reduction、Classification、Collaborative filtering、 Feature learning、Topic modelingなどに利用されている。
- Support Vector Machines
- 深いニューラルネットワーク(Deep Neural Networks)
入力層と出力層の中間に中間層(隠れ層という)が2層以上あるモデルを深いネットワークモデルといい、その上で学習可能なモデルを深層学習と呼んでいる。
- 畳み込みニューラルネットワーク
畳み込みニューラルネットワーク(CNN; Convolutional Neural Network)は画像処理の基本演算である畳み込みとプーリングを行う層で構成されたニューラルネットワークである【36】。畳み込みはフィルタ処理で使用する一般的な演算であり、画像認識の場合、畳み込み層はフィルタの濃淡パターンとアクティベーションの各位置での類似パターン(特徴という)を抽出する。
CNNはフィルタ係数を重みとして学習する。プーリングは位置感度を若干低下させることで、対象とする特徴の位置が若干変化した場合でもプーリング処理の出力が普遍になるようにする仕組みである。つまり位置情報がある程度ずれていても特徴が得られるようにする補正処理層と言える。畳み込み層とプーリング層を積層することで、下層(入力層側)での詳細な特徴の位置情報(特徴マップという)から上層(出力層側)では曖昧な(高コンテクストな)特徴マップを得て、最終的に画像中の主な特徴を認識、つまり画像認識をする。層間は下層の特定のユニットのみと畳み込み層が接続しており(図3.3(b)参照)、取得した特徴マップのブレをプーリング層で補正するのでプーリング層の入力は必ず畳み込み層になる。さらに画像の持つコントラストを補正するため正規化を行う層(正規化層)も追加する事もある。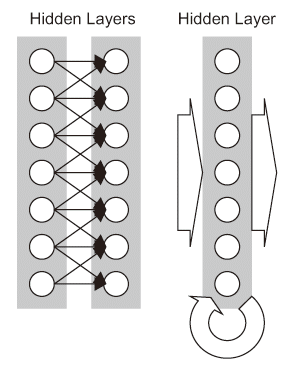 図3.3(b) Neural Network Models.: CNN
図3.3(b) Neural Network Models.: CNN - 再帰型ニューラルネットワーク
再帰型ニューラルネットワーク(RNN; Recurrent Neural Network)は系列データを扱うニューラルネットワークである【36】。系列データとは個々の要素が順序付きの集まりで与えられる要素列で構成されたデータのことで、系列の長さは一般に可変である。系列データ中から特定の特徴を認識するのに用いられる。音声認識や動画像認識のような時系列データ、テキストデータなどに利用されている。
RNNは内部に循環接続(グラフの閉路)を持ち(図3.3(c)参照)、先行する入力データの影響を記憶する機能を持つ。この記憶期間を長くする方法として、長短期記憶(LSTM; Long Short-Term Memory)という記憶できるユニット(メモリユニットという)をRNNに利用する方法がある。メモリユニットは記憶するための閉路を持つメモリセルにゲートという複数の入出力(入力ゲートと出力ゲート)とリセット(忘却ゲート)を制御するユニットが接続された構成を持つ。入出力と忘却ゲートはそれぞれ、論理回路での書き込み許可(WE; write enable)、読み出し許可(RE; read enable)、及びリセットといった制御入力を持つレジスタ回路等に相当する。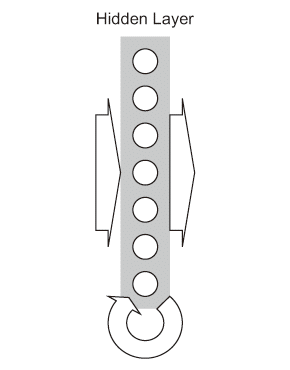 図3.3(c) Neural Network Models.: RNN
図3.3(c) Neural Network Models.: RNN - 自動符号化器
自動符号化器(AE; Autoencoder)は非再帰型順伝播ニューラルネットワークであり、任意のニューラルネットワークの入力層から最終的に推論を行う出力層の手前までの層のモデル構成を反転させたモデルを、元のネットワークモデルの出力層の手前の層に接続したネットワークモデルである【89】。M層で構成されるあるネットワークモデルの(M − 1)層にこのモデルを反転して繋げる(図3.3(d)参照)。従って、これにより2(M − 1)層で構成されたAEにおいてM層と2(M − 1)層はそれぞれ、元のモデルの出力層側、入力層側で構成される。入力データ(1層目)と2(M − 1)層の出力で再構築されたデータとの間で差異がなくなるようにパラメータを更新する様に学習する。
AEのモデルにおいて入力層から反転されている層の前までをencoder(符号器)、それ以降の出力層までをdecoder(復号器)という。この学習結果として符号器の出力から推論を得る。符号器の入力に復号器の出力を近づけるように学習させることは、符号器の出力が教師なしで学習した結果に相当する。深層学習では各層のパラメータの初期値を設定する(Pretraining; 事前学習という)のにAutoencoderを用いている【36】。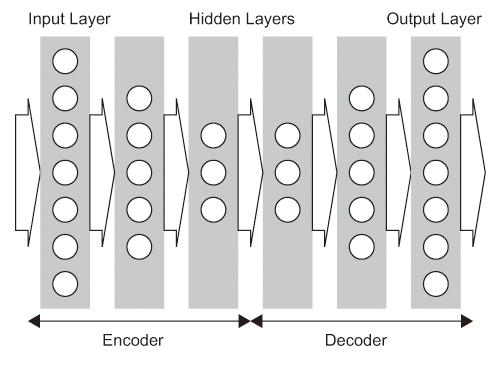 図3.3(d) Neural Network Models.: Autoencoder
図3.3(d) Neural Network Models.: Autoencoder
深層学習では以上のCNN、RNN、AEといった基本的なネットワークモデルを使用して利用者の問題向けのネットワークモデルを設計開発している。またこれらのモデルを組み合わせて新しいモデルを構成することもある。例えば、Deep Belief Network(DBN)はRBM等のネットワークモデルを積層したネットワークであり【90】、Images、Video sequences、Motion-capture dataなどの認識モデルや生成モデル(後述)に利用されている。ネットワークモデル開発で最も大きい関心は、設計に伴うハイパーパラメータを決めて設計した、より高い推論性能を持つ各層の各パラメータを得る事である。ハイパーパラメータとは機械学習モデルの学習係数や正則化係数(どちらも付録A参照)といったモデル開発時に伴うパラメータや評価などネットワークモデルの実行時に繰り返し回数(エッポック数)やバッチサイズ(後述)といった環境変数などを指している。そのための取り組みや研究もある。 - ベイズ最適化
任意のネットワークモデルのパラメータセットとそのネットワークモデルを構築する際に導入したハイパーパラメータセットの調整には、経験あるいは最適なそれらの数を探索する必要がある。感度分析、整合調整、予測などを伴う実験に利用されているガウス過程(GP; Gaussian Process)を機械学習におけるパラメータやハイパーパラメータの最適化に応用する試みがある【91】。
ベイズ最適化(Bayesian Optimization)は最小構成の関数を探索するためにその関数の確率モデルを構築して確率モデルで探索する時、次回のその関数の評価を判断する特徴を持つ。結果的に難しい非凸関数の最小構成を相対的に少数の評価回数で見つけることができる。 - 最適化アルゴリズムの学習
学習時のパラメータ更新方法について、より良いパラメータを得るための様々な最適化アルゴリズムが検討、提案されているが、そのアルゴリズム構築の多くは手動である。これに対して機械学習を利用して自動的にアルゴリズムを得る手法の提案もある【92】。任意のネットワークモデルのパラメータセットを最適化する最適化用のネットワークモデルを用意して、任意の(被最適化)ネットワークモデルの誤差情報により最適化ネットワークモデルのパラメータセットを更新し、この最適化パラメータが被最適化パラメータの更新に使用される循環を構成することで逐次パラメータの最適化を実現する。 - Deep Generative Models
何らかの確率モデルを使用して(入力)データを生成するモデルを生成モデル(Generative Model)という。一般に特定用途に対する学習用入力データを大量に生成したり、特徴を学習したパラメータを得るために使用する。特に確率モデルとディープニューラルネットワークモデルにより構築した確率変数の確率密度関数を使用したネットワークモデルをDeep Generative Model(DGM)と言う【93】。DGMはラベル有り(M2)と無し(M1)の生成モデル項で構成され、ラベル無しデータは不完全データとして扱い確率密度関数を使用する。DGMは深層学習と組み合わせることができ、その特徴学習は学習データ(訓練データ)に占める期待値であるラベル有りのデータ(訓練サンプル)の数が少数でも効率よく、一般的な深層学習ネットワークモデルの学習より高い認識率の推論ができる特徴を持つ。
- 畳み込みニューラルネットワーク
3.2.2 ニューラルネットワーク・ハードウェア
ニューラルネットワークの内積演算の実装アプローチとして、デジタル回路(Digital Logic Circuit)とアナログ回路(Analog Logic Circuit)による実装がある。ここでは一般的なデジタル回路実装について説明する。内積演算のアナログ回路実装はニューロモルフィックコンピューティングのものと同様である。
ニューラルネットワークの基本ハードウェア構成を図3.2(b)に示す。DendriteはMAC(Multiply-Accumulate)演算器で構成され、アクティベーション(ベクトル)の次数nに合ったパラメータをストアしているパラメータメモリから読み取ってアクティベーションの要素とパラメータの要素間で積算を行い、その値を累算(Accumulate)する。Unitは主に活性化関数で構成され、累積結果の値を活性化関数(AF)へ入力する。DendriteとAFで構成されたSomaを複数並べて、入力ベクトルの要素値を共有することでニューロモルフィックコンピューティング同様に並行処理を行う。各活性化関数の出力値は Conductorを通して出力、あるいは自身にフィードバックされる。
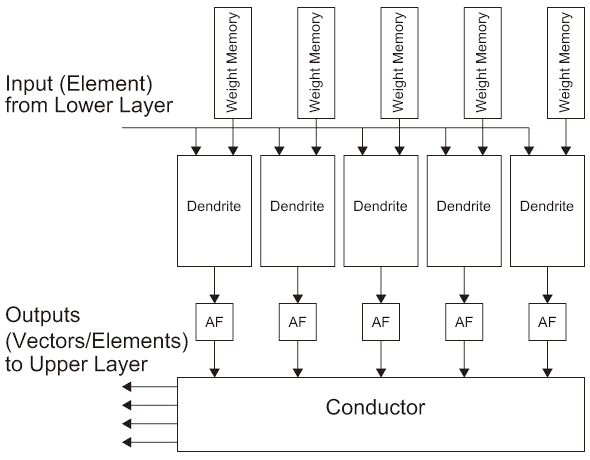
図3.2(b)は一つの入力ベクトル x ϵ Rn の要素に対してMAC演算を行うので、n次元のベクトルの場合n回のMAC演算を要する。これに対し一つのSoma内に複数のMAC演算器を用意しておき、パラメータ列(ベクトルとして扱う)とアクティベーションをそれぞれ分割して作成した各サブベクトルを各MAC演算器で累積演算を行い、最終的に得られる複数の累積値の総和を取りAFへ入力する方法も可能である。このようなMAC演算器を基にした方法以外の内積演算を高速に行うためのアプローチは主に二つある。
- Adder-Tree方式
先に述べたように複数のMAC演算器を並べるのではなく、図3.4(a)に示すように積算器を複数用意してアクティベーションの要素と対象パラメータの要素の積算を同時並行に行い、その複数の積算結果を加算器で構成されたAdder-Treeと呼ぶ木トポロジの加算回路により(部分)総和の演算を行う。実装してあるAdder-Treeより規模が大きい内積演算の場合、図3.4(a)に示す最終段の累算器でベクトルを分割した各サブベクトルの複数の時系列の部分内積演算結果を累算する。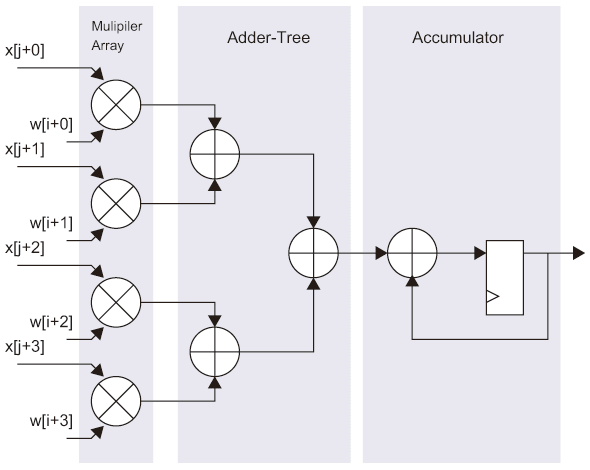 図3.4(a) Dot-Product Operation Methods.: Adder-Tree Method.
図3.4(a) Dot-Product Operation Methods.: Adder-Tree Method. - Systolic-Array方式
複数の規則的に並べられた演算回路(PE; Processing Element)をデータの依存性パターンを考慮して規則的に繋げたアレイ(Systolic-Arrayという【94】)上で演算を行う。一般に並べる演算回路は全て同じであり、行列演算に利用されることが多い。図3.4(b)は行列積演算を一次元アレイとして実装する場合の例を示す。実装しているSystolic-Arrayより規模が大きい行列を扱う場合、一般にサブベクトルの行列演算を繰り返すことで結果を得られる。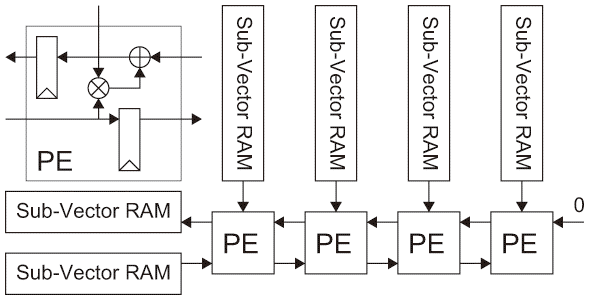 図3.4(b) Dot-Product Operation Methods.: Systolic-Array Method.
図3.4(b) Dot-Product Operation Methods.: Systolic-Array Method.
MAC演算器を基にしたアプローチは典型的な時系列処理であり、Adder-Tree方式は空間展開処理の典型的な例である。Systolic-Array方式はデータ依存性を基にこのデータフローグラフを時間軸上と空間上にグラフを破壊しない範囲で自由に展開でき、トレードオフ(或いは積極的なコーディネーション)が可能である【95】。一般にSystolic-Array方式を使用したハードウェアは特定のコーディネーションを固定して実装している。このコーディネーションを実装後にある程度柔軟にしたアプローチは再構成可能計算機(RC; Reconfigurable Computing)と呼ばれ、典型的なデバイスはFPGAである。一般に1bitの細粒度の計算ノードであるCLB(後述)を一般的な8bitや32bit等のデータ幅を持つ演算器に置き換えたアーキテクチャを粗粒度再構成可能アーキテクチャ(CGRA; Coarse-Grained Reconfigurable Architecture)と呼んでいる【96】。
■
次回は、「第4章 機械学習ハードウェア、4.1 実装プラットフォーム、4.2 性能指標」を転載します。
【参考文献】
- 【36】(2)(3) 岡谷 貴之. 深層学習. 機械学習プロフェッショナルシリーズ. 講談社, 1st. edition, April 2015.
- 【85】 Corinna Cortes and Vladimir Vapnik. Support-Vector Networks. Mach. Learn., 20(3):273-297, September 1995.
- 【86】 Asja Fischer and Christian Igel. An Introduction to Restricted Boltzmann Machines, pages 14-36. Springer Berlin Heidelberg, Berlin, Heidelberg, 2012.
- 【87】 JIS. JIS Z 8101-1 : 1999. http://kikakurui.com/z8/Z8101-1-1999-01.html.
- 【88】 Ruslan Salakhutdinov, Andriy Mnih, and Geoffrey Hinton. Restricted Boltzmann Machines for Collaborative Filtering. In Proceedings of the 24th International Conference on Machine Learning, ICML '07, pages 791-798, New York, NY, USA, 2007.ACM.
- 【89】 D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Vol. 1, chapter Learning InternalRepresentations by Error Propagation, pages 318-362. MIT Press, Cambridge, MA, USA, 1986.
- 【90】 G. E. Hinton. Deep belief networks. 4(5):5947, 2009. revision #91189.
- 【91】 J. Snoek, H. Larochelle, and R. P. Adams. Practical Bayesian Optimization of Machine Learning Algorithms. ArXiv e-prints, June 2012.
- 【92】 Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W. Hoffman, David Pfau, Tom Schaul, and Nando de Freitas. Learning to learn by gradient descent by gradient descent. CoRR, abs/1606.04474, 2016.
- 【93】 Diederik P. Kingma, Danilo Jimenez Rezende, Shakir Mohamed, and Max Welling. Semi-Supervised Learning with Deep Generative Models. CoRR, abs/1406.5298, 2014.
- 【94】 Sun-Yuan Kung. On supercomputing with systolic/wavefront array processors. Proceedings of the IEEE, 72(7):867-884, July 1984.
- 【95】 D. I. Moldovan. On the design of algorithms for VLSI systolic arrays. Proceedings of the IEEE, 71(1):113-120, January 1983.
- 【96】 Reiner Hartenstein. Coarse Grain Reconfigurable Architecture (Embedded Tutorial). In Proceedings of the 2001 Asia and South Pacific Design Automation Conference, ASP-DAC '01, pages 564-570, New York, NY, USA, 2001. ACM.
※以下では、本稿の前後を合わせて5回分(第6回~第10回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
6. 機械学習のハードウェア化の歴史と、深層学習の登場
1980年代~現在まで、機械学習のハードウェア実装の歴史を振り返る。計算機アーキテクチャの行き詰まりと深層学習の登場により、機械学習ハードウェアの研究が進んできたことを紹介する。
7. 機械学習のニューロモルフィック・コンピューティング・モデル
機械学習ハードウェアの「ニューロモルフィック・コンピューティング」(前者)と「ニューラル・ネットワーク」という大分類のうち、脳の構造と神経細胞(ニューロン)発火の仕組みを模倣した前者のモデルを説明する。
8. 【現在、表示中】≫ ディープラーニングを含むニューラルネットワーク・モデルと、そのハードウェア実装
一般的なニューラルネットワークモデルとディープラーニング(深層学習)について紹介。さらにそのハードウェアを実装するための一般的な方法を説明する。
9. 機械学習ハードウェアとは? 実装基盤となるメニーコアプロセッサ/DSP/GPU/FPGAのアーキテクチャ概説
機械学習ハードウェアとは、設計開発した機械学習モデルを実行するハードウェアプラットフォームのことだ。その実装プラットフォームとなる「CPUを含むメニーコアプロセッサ」「DSP」「GPU」「FPGA」のアーキテクチャについて概説する。
10. ディープラーニング(深層学習)の基本: 数式モデル
ディープラーニング(深層学習)の一般的なネットワークモデルである「順伝播型ニューラルネットワーク」の、各ユニットにおける演算を表現する数式モデルを示しながら、その意味を説明する。