
書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(12)
深層学習と行列演算 ― ディープラーニングの基本
「深層学習の行列表現とそのデータサイズ」「行列演算のシーケンス」「パラメーターの初期化」について説明する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「付録A 深層学習の基本、A.2 機械学習ハードウェアモデル」を転載しました。今回は、「A.3 深層学習と行列演算」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
A.3 深層学習と行列演算
前項では任意のl層の任意のjユニットの出力zj(l)を得る数式と、誤差逆伝播における勾配降下法による重みwji(l)の更新について数式で表現した。ここでは各出力や重み等の個々の計算を一つのマトリックスやベクトルにまとめる事で、任意のl層の順伝播と逆伝播演算を簡潔に表現し、その各マトリックスやベクトルで表現される各変数のデータサイズも併せて検討する。
A.3.1 深層学習の行列表現とそのデータサイズ
活性化関数に入力する値のベクトル表現したU(l)は、重みのマトリックスW(l)と入力ベクトルZ(l − 1)による行列積演算とその結果へのバイアスで構成されたベクトルB(l)を加算する次のようなアフィン変換で表現できる。
式A.7
W(l)にB(l)を定数値として含ませて(J × (I + 1))のマトリックスとして、Z(l − 1)に定数1の要素を追加する事で(I + 1)のベクトルとし、式A.7を単純にU(l)=W(l)Z(l−1)と表現できる。ここでは一般的なこの式ではなく式A.7を使用して説明する。
l層での出力Z(l)は単にU(l)の各要素に対して活性化関数へ入力した値をまとめて得たベクトルであり、次の様に書ける。
式A.8
ミニバッチにおける、l層のjユニットのδj(l)を要素に持つ、この層でのユニット数Jを行、ミニバッチサイズNを列とする行列Δ(l)は次のように行列演算で表記できる【36】。
式A.9
演算子⊙は各要素間の積算を表す。これにより、更新量∂W(l)と∂b(l)も次のように行列演算で計算することができる【36】。
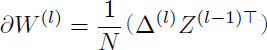
式A.10
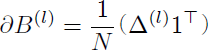
式A.11
上記式から行列及びベクトルの転置(式中⊤表記)が必要となる事が分かる。
表A.2と表A.3はミニバッチサイズNによる推論と学習において必要になる各マトリックスとベクトルのデータレイアウトを示し、データ規模も示している。任意のl層における各マトリックスやベクトルのデータサイズとそれらの要素のデータサイズ(データ型上のデータ幅或いはそのbit数)の積算からそのマトリックスやベクトルのl層でのデータサイズを得る。
| Array | Z(l − 1) | W(l) | B(l) | f ′(l)(U(l)) | Z(l) |
|---|---|---|---|---|---|
| I/O | IN | IN | IN | OUT | OUT |
| Layout | I × N | J × I | J × 1 | J × N | J × N |
| Array | W(l + 1) | Δ(l + 1) | f ′(l)(U(l)) | Δ(l) | ∂W(l) | ∂B(l) | Z(l − 1) |
|---|---|---|---|---|---|---|---|
| I/O | IN | IN | IN | OUT | TEMP | TEMP | IN |
| Layout | K × J | K × N | J × N | J × N | J × I | J × 1 | I × N |
A.3.2 行列演算のシーケンス
ミニバッチによる学習の手順はl = Lからl = 1まで次のシーケンスを繰り返す。
- W(l)とB(l)を初期化
- l = Lの時:Δ(L)の計算(平均二乗誤差等の誤差関数の並列演算)
- l ≠ Lの時:Δ(l)の計算(行列積と要素毎積算)
- ∂W(l)と∂B(l)の計算(行列積)
- ∂W(l)と∂B(l)でパラメータの更新(行列減算)して3へ戻る
この様にシーケンス自体は極めて単純である。ハードウェアが許容できるマトリックス・ベクトル演算のサイズ以上の演算が伴う場合、そのマトリックスやベクトルを分割して演算を行い、最終的な演算結果を得るサブシーケンスが必要になる。それに伴うデータは表A.2と表A.3に挙げた通りである。推論は5つのデータセットを扱い、学習は7つデータセットを扱う必要がある。これらのデータを効率よく供給する必要がある。
A.3.3 パラメータの初期化
パラメータはランダムに初期化する必要がある。各パラメータが同じ値を持つと仮定すると、連続した全結合層におけるユニットは全て同じ値を持ち均一な状態となり、複数のパラメータを持つ意味がなくなる。従って、個々のパラメータは少なくとも何らかの異なる値を持つ必要があるのである。
アクティベーションの要素を一様な分布とした“Xavierの初期値”を用いるとネットワークモデルが良く学習できる事が知られている【226】。Xavierの初期値は前の層のユニット数をnとした時、1/√n の標準偏差を持つ分布を使用する初期化方法として現在広く使用されている。一様な分布でないReLU関数を使用する場合は“Heの初期値”を用いて対処する【220】。Heの初期値は前の層のユニット数をnとした時、2/√n を標準偏差とするガウス分布を使用して初期化する。
■
次回は、「付録A 深層学習の基本、A.4 ネットワークモデル開発時の課題」を転載します。
【参考文献】
- 【36】(2) 岡谷 貴之. 深層学習. 機械学習プロフェッショナルシリーズ. 講談社, 1st. edition, April 2015.
- 【220】 Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. CoRR, abs/1502.01852, 2015.
- 【226】 Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Aistats, volume 9, pages 249-256, 2010.
※以下では、本稿の前後を合わせて5回分(第10回~第14回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
10. ディープラーニング(深層学習)の基本: 数式モデル
ディープラーニング(深層学習)の一般的なネットワークモデルである「順伝播型ニューラルネットワーク」の、各ユニットにおける演算を表現する数式モデルを示しながら、その意味を説明する。
11. 機械学習ハードウェアモデル ― 深層学習の基本
深層学習における、パラメーター空間と順伝播・逆伝播演算の関係を説明。また、代表的な学習の最適化方法と、パラメーターの数値精度についても紹介する。
12. 【現在、表示中】≫ 深層学習と行列演算 ― ディープラーニングの基本
「深層学習の行列表現とそのデータサイズ」「行列演算のシーケンス」「パラメーターの初期化」について説明する。
13. ネットワークモデル開発時の課題 ― 深層学習の基本
訓練と交差検証で誤差率が高い場合は、バイアスが強い「未適応状態」もしくはバリアンスが強い「過適応状態」である。このバイアス・バリアンス問題の調整について概説。
14. CNN(畳み込みニューラルネットワーク)/RNN(再帰型ニューラルネットワーク)/AE(自動符号化器)の応用モデル
CNN、RNN、AEといったネットワークモデルを拡張あるいは組み合わせた「Deep Convolutional Generative Adversarial Networks」「Highway Networks」「Stacked Denoising Autoencoders」「Ladder Networks」「Residual Networks(ResNet)」を紹介する。