C#エンジニアのためのBigQuery入門(1)
誰でも簡単に超高速なクエリができるBigQueryとは?
知らないと損! 使わないと損! これからのデータ解析に必須のBigQueryの概要を紹介。また、Webコンソールからのクエリ実行の基礎を解説する。
BigQueryとは
「BigQuery」というサービスをご存じだろうか。2014年後半より徐々に話題になり、利用事例も公表され始めたため、「名前は聞いたことがある」という方も少なくないのではないかと思う。
BigQueryはGoogle Cloud Platformが提供するビッグデータ解析サービスである。いわゆる「ビッグデータ解析サービス/ソフトウェア」はいくつもあるが、BigQueryは数TB(テラバイト)あるいはPB(ペタバイト)に及ぶデータセットに対し、SQLに似たクエリを実行し、数秒あるいは数十秒程度で結果を返すというサービスである。
実際の実行例を見てみよう。
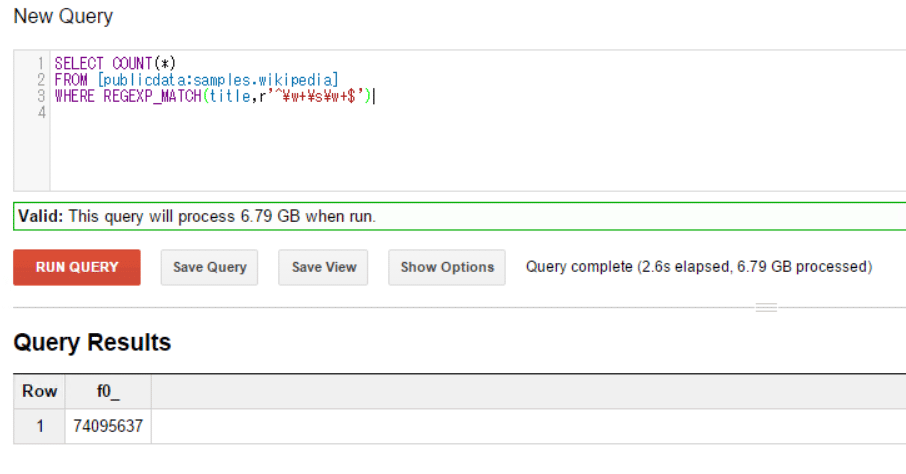
クエリの結果は74095637(約7410万)で、6.79GB(ギガバイト)のデータをスキャンしたことが確認できる。
図1を見ると分かるように、クエリ構文自体はSQLによく似ており、その文の意味もSQL的に解釈して問題ない。図1の例では、Wikipediaの情報を集めた、約3億行のテーブルに対して正規表現で検索している。フルスキャンが必要なクエリであるが、BigQueryは2.6秒で結果を返している(=2.6s elapsedと表示されている)。この正規表現が特別に高速な例というわけではなく、正規表現を変更しても同程度の時間でレスポンスが返る。
本連載では、数回にわたってBigQueryの使い方を解説する。データの投入元や、クエリを実行するクライアント側のOSは、Windows ServerおよびWindowsを想定しており、BigQueryのAPIを.NET SDKを利用してC#で実行する。
メインターゲットはC#で開発しているエンジニアである。BigQueryは、APIがそろっているため、C#(およびそれ以外の言語)でもメリットを享受できる。ぜひ使ってみて、グーグルの誇るビッグデータ解析サービスの仕組みと、そのメリットを感じていただきたい。
なお、今回の記事は「導入編」ということで、概要の説明と、Web画面からの操作を説明する。そのため、C#コードは出てこない。C#によるデータの挿入やクエリの実行は本連載の第2回以降を待っていただきたい。
BigQueryの歩み
BigQueryはもともとグーグル社内で使われていたDremelと呼ばれるサービスが基になっている。Dremelは2010年に論文が公開され、クローズドにリリースされている。大規模データに対してアドホックなクエリを実行するためのサービスであり、グーグル社内では非エンジニアも利用している。
そして、2012年に正式にリリースされ、継続的にバージョンアップされてきた。2014年3月にはStreaming Insertもサポートし、利用事例の公開も目立つようになってきた。今後もユーザー定義関数の追加など、いくつかの機能追加がすでに予告されている。
BigQueryの仕組み
BigQueryを特徴づけている仕組みとしては、カラム指向なデータ配置とツリーアーキテクチャが挙げられている。いわゆる伝統的なRDBMS(リレーショナル・データベース管理システム)では、データはレコード指向に配置されている(図2)。レコード指向(=行指向)であれば、1件のレコード全体を同じストレージに配置するが、カラム指向(=列指向)では1件のレコードをカラムごとに分割して別々のストレージに配置する。
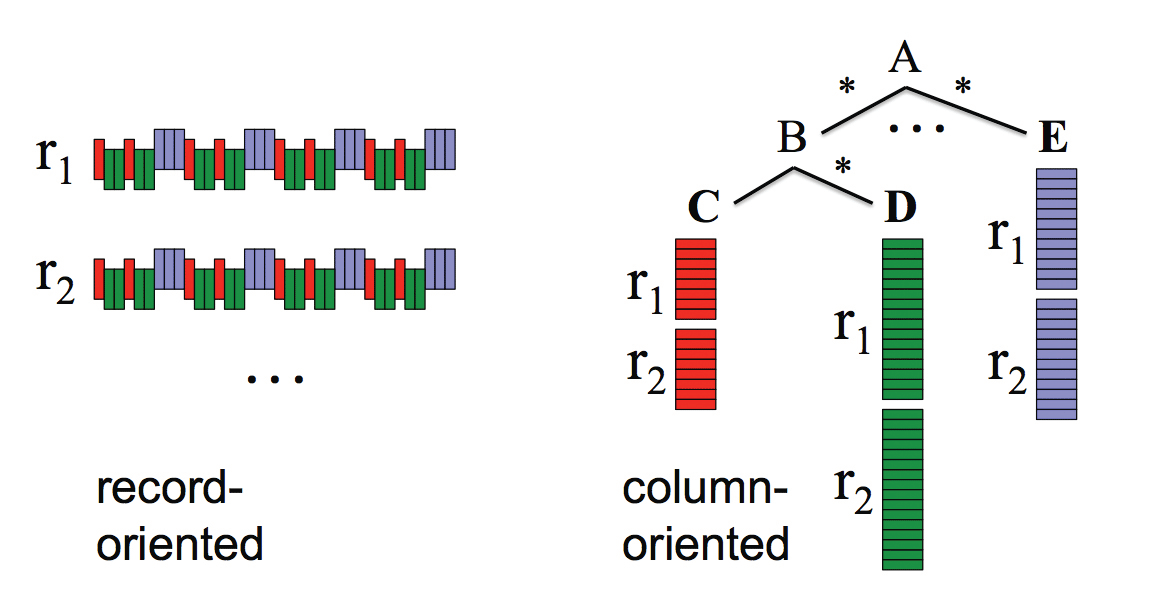
論文より引用。
カラム指向自体は、データの集計処理に強いデータウェアハウスでも使われてきた技術であり、トラフィックの最小化と圧縮効率の上昇に効果がある。カラム指向でデータを配置していると、クエリで必要な列に対してのみアクセスすればいいことがトラフィックの最小化につながる。また、1つの列は同じような値が出ることが多いため、データ圧縮の効率が行指向だと約1/3になるのに対し、カラム指向だと1/10まで圧縮できると、あるレポートで報告されている。
一方、クエリを実行する際、ツリーアーキテクチャと呼んでいる機構で、クエリを分割統治している(図3)。カラム指向で配置したデータを並列にスキャンし、そこで読み取った結果を高速に集約してクエリの結果を出している。
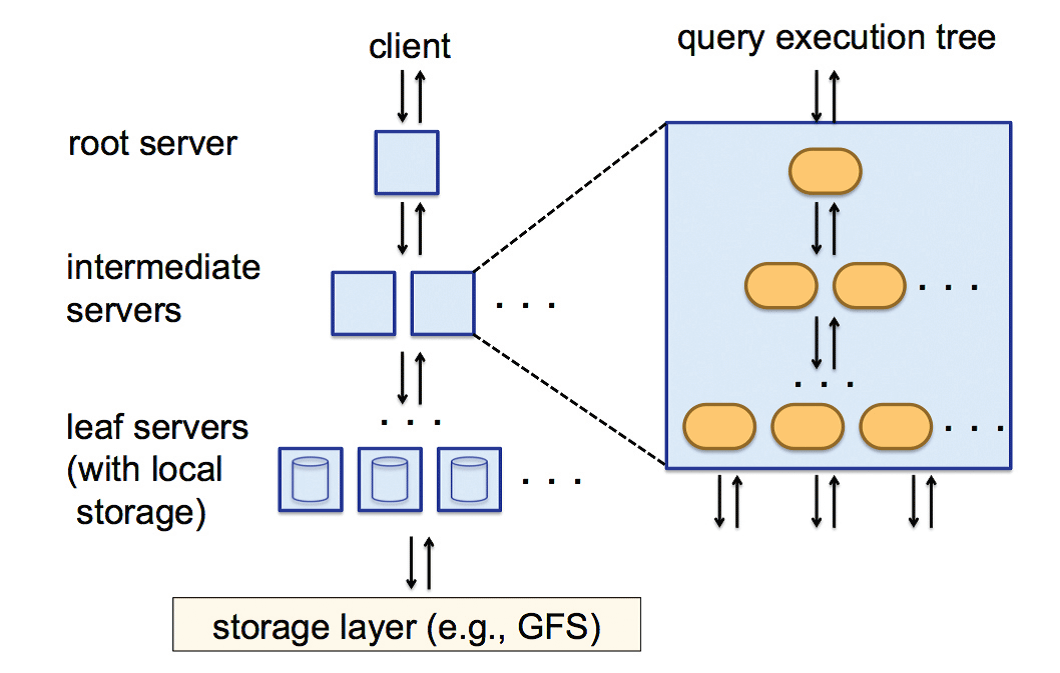
図2と同じ論文より引用。
この2つの技術は、グーグル独自の技術というわけではない。しかし、ハードウェアから構築している、既存のグーグルのクラウド技術を活用し、パブリックなクラウドサービスとして提供可能なレベルの実装になっている点がGoogle BigQueryの強みとなっている。
BigQueryの特徴
他の類似サービスとの比較
巨大データを処理する技術としては、同じグーグルが使ってきたMapReduceというものがある。MapReduceとBigQueryを比べると、MapReduceが巨大なデータを安定的に処理できるプログラミングモデルであることに対し、BigQueryはアドホックにトライ&エラーしながらクエリを実行するサービスであることが異なっている。
MapReduceは、非構造化データを、プログラミングモデルを通して扱うことができ、巨大なテーブルの結合や巨大な出力結果のエクスポートも可能である半面、処理時間は数分間から数日に及ぶ。BigQueryは、あらかじめデータを構造化してBigQueryのテーブルに格納しておかねばならないが、ほとんどのクエリは数秒で完了する。
一方、他社のサービスと比べてみると、Amazon Redshiftは比較的BigQueryに近い領域といえよう。PostgreSQLドライバーを用い、PostgreSQLによく似た感覚で巨大データに対してクエリを実行できる。ただ運用面に関して言えば、BigQueryが、カラムのデータ型を定義して、テーブルにデータを挿入しさえすれば、その後の管理がほぼ不要であるのに対し、Redshiftではカラムの圧縮型を事前に定義しておく必要があり、データノードのサイジングを管理するなどの運用作業が発生する点が異なる。
Azure Event HubsやAmazon Kinesisは、BigQueryやMapReduceとはまた違った特徴を持つサービスである。これらはバッチやアドホックな処理はできないが、大量に流れてくるデータのストリームに対してリアルタイムの処理が可能である。今後のトレンドとして押さえておきたいサービスである。
BigQueryのユースケースと課金体系
前の章で述べたように、BigQueryは事前にテーブル構造を決めてデータを挿入しておく必要がある。そのため、アクセスログやアプリケーションのログを随時BigQueryに挿入しておき、日次のレポートで解析したり、障害時に抽出条件を変えながら調査を行ったりするのが、代表的なユースケースではないだろうか。
データの挿入については、Streaming Insertを使うと頻度にもよるが秒程度のオーダーでのリアルタイムな挿入が可能になる。また、CSVもしくはJSON形式のファイルによる挿入も可能だ。ファイルはGoogle Cloud Storage上にアップロードしたものが対象となる。データの挿入について連載第2回で詳細に説明する予定だ。
BigQueryの魅力の1つに、値段の安さもある。課金対象となるものは大きく3つあり、保管しているデータ量、Streaming Insertの行数、クエリの際にスキャンしたデータ量、である。データ量は1Gbytesの1月単価で$0.02(本稿では「$」は「米ドル」を表す。※以下いずれも執筆時点の価格情報なので最新情報は公式ページを参照されたい)であり、これはいわゆる「クラウドストレージ」としての単純なデータ保管料と比べてもかなり安い部類に入る。そのため、クエリを実行する予定はないが、取りあえずログを保管する目的としてBigQueryを利用することも十分に値する。
Streaming Insertは、2015年1月より課金が開始された。10万行のStreaming Insertで$0.01であるため、大量のデータをStreaming Insertしない限りは、これが問題にはなりにくいであろう。なお、Streaming Insertを使わないファイル経由でのデータの挿入に関しては無料である。
クエリの際にスキャンしたデータ量による課金は1Tbytesに付き$5である。BigQueryのクエリは、基本的にフルスキャンになってしまうが、必要なカラムだけを指定したり、Table Decoratorsと呼ばれる機能を使ったりすることでスキャン対象のデータ量を減らすことも可能である。
BigQueryを始めてみよう
それでは実際にBigQueryを使ってみよう。
基本的には有料のサービスであり、事前にクレジットカードを登録しておく必要がある。しかし一定の枠内でのクエリ実行は無料であり、Googleやそのほかのユーザーが公開しているパブリックなデータセットに対して、その枠内のクエリを実行する場合は、クレジットカードの登録は不要である(それ以外の操作については、無料枠の範囲内であってもクレジットカードの登録が必要である)。
そこで連載第1回である本稿では、クレジットカードの登録が不要な範囲内でBigQueryを試してみよう。
GoogleアカウントとGoogle Cloudプロジェクトの作成
事前に必要なのはGoogleアカウントの作成だ。持っている人も多いと思われるが、新規に作成する場合は「Googleアカウントの作成」から作成してほしい。
Googleアカウントにブラウザーでログイン後、「Google Cloudのコンソール」にアクセスする。初めてアクセスした場合は、プロジェクトの作成を求められるはずだ(図4)。各自、好きなプロジェクト名(※アルファベットを用いた名前にする必要がある。本稿の例では「BigQueryTest」)を付けてほしい。
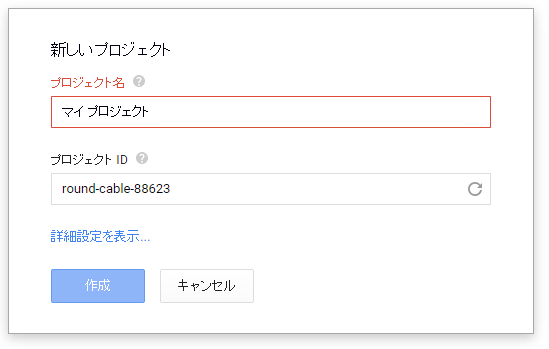
[プロジェクト名]の初期入力値は日本語だが、そのままだとエラーになるため、アルファベットを用いた名前に変更してほしい。また、[プロジェクト ID]はGoogle Cloud上で一意になっている必要があり、右側の[更新]ボタンを押すと、自動生成してくれる。
BigQueryのWebコンソールとサンプルデータセット
作成後、画面の左側がこのように(図5)なっているはずだ。
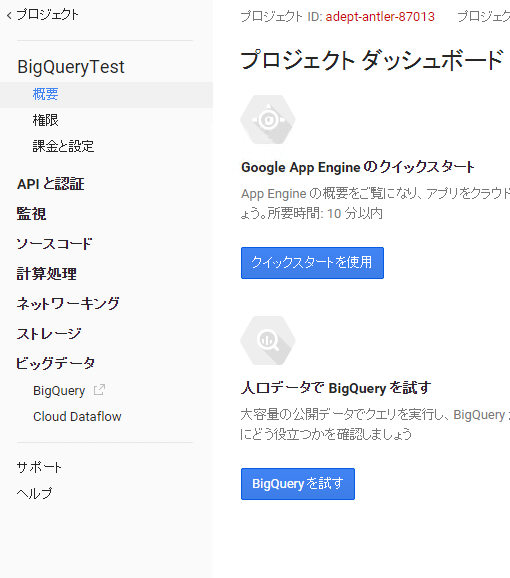
プロジェクト名、プロジェクトIDは図4で入力した値が使われる。
すでに作成している場合、先ほどのGoogle Cloudのコンソールを開くと、図6のようにプロジェクト一覧が表示されるので、作成したプロジェクトのリンクを開く。これにより図5のような画面に移動する。
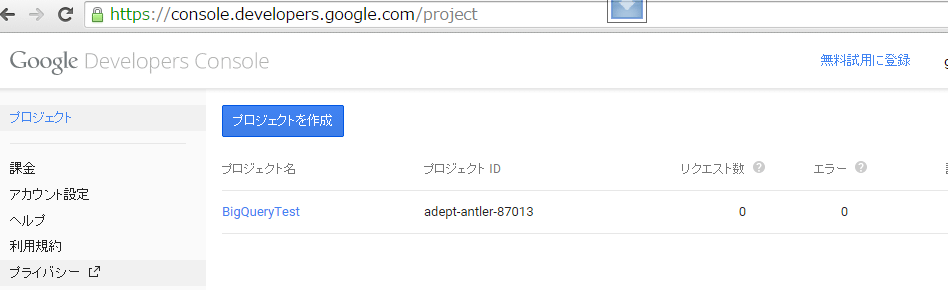
プロジェクト名がリンクになっており、開くとプロジェクトの画面(図5)に移動する。
図5の[ビックデータ]の下にある[BigQuery]という項目のリンクを開くと、次(図7)のような画面が開くはずだ。これがBigQueryのWebコンソールである。
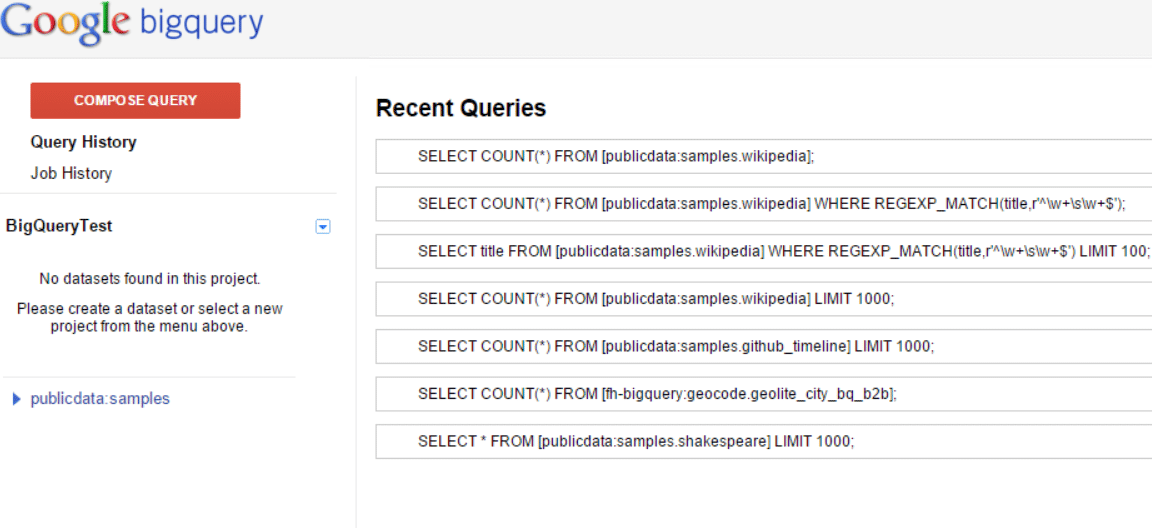
左側のメニューで[Query History]を選択すると、右側のペインにある[Recent Queries]には、以前実行したクエリが表示される。
図7の左下にある「publicdata.samples」というのが、グーグルが提供しているパブリックなデータセットのサンプルである。左側の三角マークを選択して展開すると、テーブル一覧(図8)が表示される。
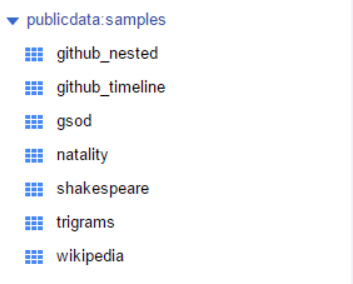
BigQueryのデータセットとテーブルの基礎
BigQueryでは、RDBと同じようにスキーマを持ったテーブルが存在し、複数のテーブルをまとめる単位としてデータセットが存在する。
さて、このテーブルのうち、「wikipedia」を選択してみよう(図9)。
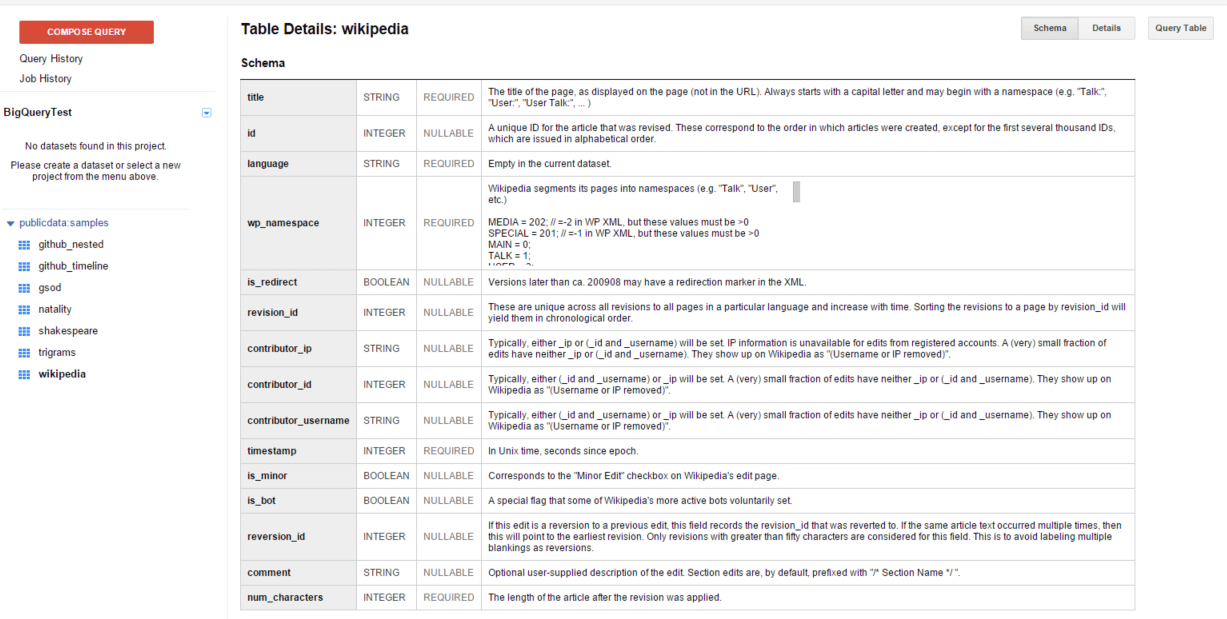
このようにテーブルのスキーマが表示される。
次に、右上に出てきたタブで[Details]を選択してみよう(図10)。
![図10 「wikipedia」の[Details]を開いた状態](https:///re.buildinsider.net/web/bigquery/01/10.gif)
テーブルのサイズなどの詳細情報、入っているデータのサンプルなどが表示される(※しかし、API経由で作成したテーブルのサイズは表示されなかったり、データのサンプルは必ずしもテーブル内部のデータと表示が一致しないケースもあったりするため、注意が必要である)。
BigQueryで初めてのクエリ
それでは、さきほどのタブの隣にある[Query Table]タブを選択して[New Query]画面を表示し、そこにクエリを入力してみよう(図11)。[New Query]画面では、すでにクエリの大部分が入力されているが、このままでは、このクエリはエラーになる。入力欄の右下にある赤い!アイコンを選択すると、クエリのエラー内容が表示される。
![図11 「wikipeia」の[Query Table]タブを開き、右下の(!)アイコンをクリックした状態](https:///re.buildinsider.net/web/bigquery/01/11.gif)
クエリ入力欄の下に、赤色の帯でクエリのエラー内容が表示されている。
このエラーを回避するために今回は、SELECTとFROMの間にCOUNT(*)と入力してみよう。緑色の帯になって、クエリがスキャンするデータ量が表示される。WHERE句などの条件がない場合の、COUNT(*)は、スキャンするデータ量が0B(=0バイト)という扱いになっている(つまり、課金対象となるクエリ時のデータスキャン量に加算されない)。
構文にエラーがないことが分かったので、[RUN QUERY]を押して、そのクエリを実行してみよう(図12)。クエリの結果が下の欄に表示される。
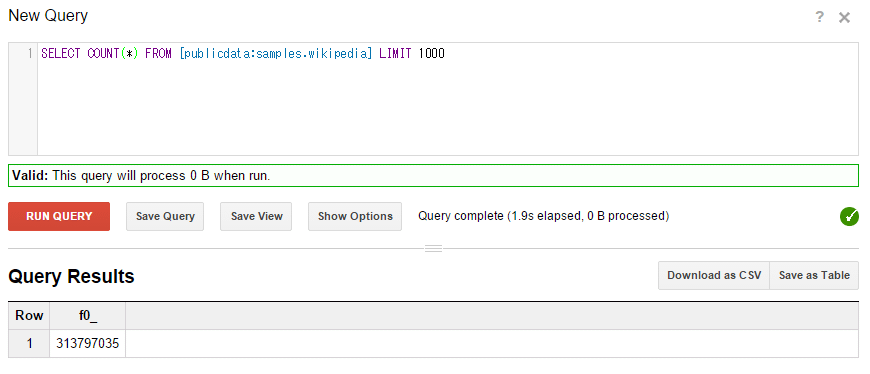
入力欄の下のメッセージが緑色の帯になっており、このクエリの実行で「0B」のデータをスキャンすると表示されている。クエリの実行結果は下に表示されている。
このように、結果は画面上に表示される。結果は、CSVとしてダウンロードしたり、別テーブルとして保存したりすることも可能だ。
BigQueryの実用ポイント
BigQueryのクエリは、かなりRDBMSの文法と近い。そのため、RDBMSでSQL文を書いたことがあるエンジニアは、RDBMSと同じイメージでSQL文を書いて実行してみるのもいいだろう。SQLのクエリの詳細については、Googleのリファレンス(英語)を参照するのがよい。なお繰り返しになるが本連載では、APIを利用してC#からさまざまなクエリを実行する方法を説明する予定である。
スキャンするデータ量は1Tbytesまでが無料の枠内であるため、制限が気になる場合は、実行する前に図11にあるスキャン量を確認するのがいいだろう。
さて、いくつかBigQuery特有の事項について取り上げてみたい。RDBMSでも使うことのある、COUNT DISTINCTだが、BigQueryでは概算値が返ってくる(図13)。正確な値が必要な場合は、GROUP EACH BYとCOUNT(*)を組み合わせる(図14)といいだろう。
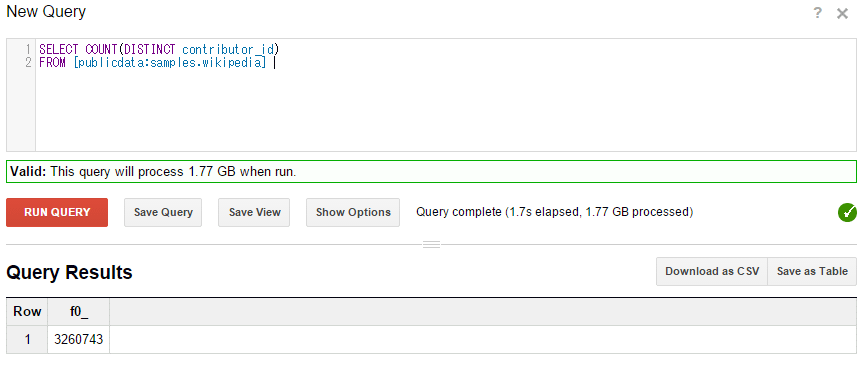
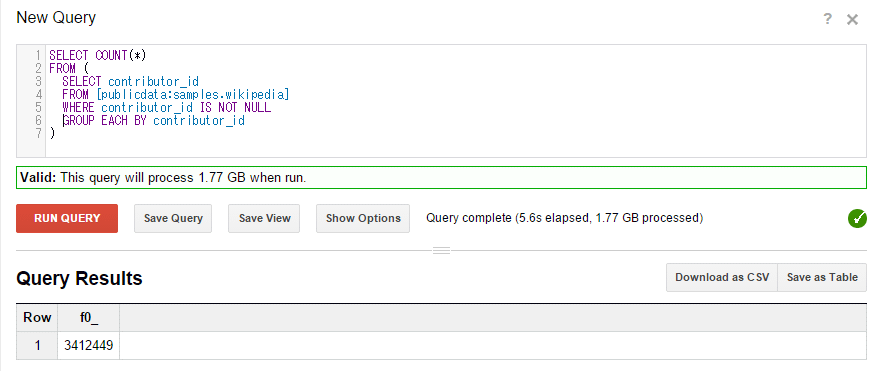
図13と図14の結果は異なっており、実際には図13の「COUNT DUSTINCT」の方が概算値になっている。
便利なエイリアスとして、TOPというものがある。これはGROUP BY ~ ORDER BY ~を短く記述できるもので、COUNT(*)と合わせて使う(図15)。
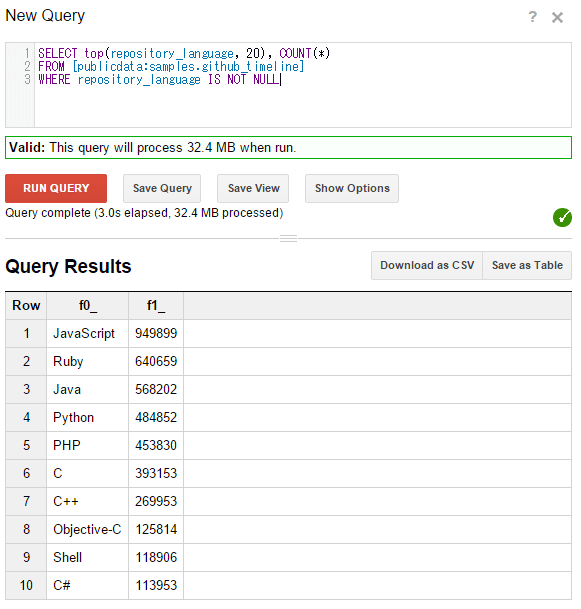
別のサンプルテーブル「github_timeline」を使って、プログラミング言語別(repository_language)にリポジトリの数をCOUNTし、降順に並び替えて、上位から10項目を取得した結果
クエリを実行しているデータセットだが、プロジェクト作成時にデフォルトで表示されるのは、グーグルが提供しているサンプルである。このサンプルデータセットの他に、ユーザーがパブリックに公開しているデータセットも、クレジットカードの登録なしにクエリを実行できる(データセットに対し、特定のユーザーにのみ公開する機能もついている)。
例えば、グーグルの協力の下、GDELTプロジェクトがパブリックなデータセットを公開している。このプロジェクトは、世界中で起きているさまざまなイベントが、どのようなトーン(=賛否)で報道されているのかというのをまとめたデータベースになっている。
使い方は簡単で、GDELTが公開しているBigQueryのデータセットのURLにアクセスするだけである。アクセスすると、図16のようにBigQueryのWeb画面の左側にデータセットが追加され、そのデータセットについてクエリが実行できるようになる。
左側のデータセット一覧に、GDELTが公開しているBigQueryのデータセットが追加されている。
パブリックなデータセットはこの他にも、GitHub Archiveのデータセットなどがあり、例えばRedditのWiki(英語)に、そういったパブリックなデータセットの一覧が掲載されている。
■
以上、駆け足になったが、BigQueryの概要から使い方をまとめてみた。
第2回以降は、「C#からBigQueryを扱う」ということで、データの投入、クエリの実行、の順で説明していきたい。が、BigQuery APIを利用する前準備として、C#からBigQueryに限らずGoogleのAPIを実行する場合に利用できるGoogle APIs Client Library for .NETの認証方法について連載番外編として説明する。
※以下では、本稿の前後を合わせて5回分(第1回~第5回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
1. 【現在、表示中】≫ 誰でも簡単に超高速なクエリができるBigQueryとは?
知らないと損! 使わないと損! これからのデータ解析に必須のBigQueryの概要を紹介。また、Webコンソールからのクエリ実行の基礎を解説する。
2. Google API Client Library for .NETの使い方
BigQueryをはじめ、GoogleのほとんどのサービスはAPIが提供されている。これを.NETから利用するためのライブラリの基本的な使用方法を解説する。
5. LINQでBigQuery: データスキャン量を抑えたクエリの実行方法
膨大なデータへのクエリで、スキャン量を減らしてクエリの課金額を抑えるには? テーブルワイルドカード関数とテーブルデコレーターを説明する。