C#と文字コード(後編)
Unicodeと、C#での文字列の扱い
進化の過程で煩雑な文字コード体系になっているUnicodeは、プログラミングでの取り扱いが面倒だ。C#とUnicodeの関係はどうなっているのか? C#が抱える課題とその解決策について見てみよう。
前編では、文字コード、そしてUnicodeがこれまでにどのような進化の道程を歩んできたかを見た。そこで説明したように、文字コード自体が結構な複雑さになっている。当然、プログラミング言語における文字列の扱いにも面倒が付きまとう。
後編である今回は、C#のstring型がどういう実装になっているかや、現状抱えている課題、それに対して検討している解決策などについて説明していく(以下、文字コードは全て16進数で表記する)。
文字列型
まずは、プログラミング言語内部での文字列の扱いについて話そう。Unicodeの歴史で話した通り、もともと、Unicodeは2Bytes固定長の文字コードで、その延長線上にあるのがUTF-16である。このことから、Unicode登場初期に生まれたプログラミング言語では、文字列の内部表現がUTF-16になっているものが多い。C#もそうなっている。
一方で、1990年代の資産があまり関係ないプログラミング言語、特にWebでよく使われるものは、文字列の内部表現にUTF-8を使っていることが多い。C#などのUTF-16な言語でも、UTF-8を直接取り扱える方法が求められている。
UTF-8の取り扱いに関しては「オピニオンコラム:岩永信之(7): 次期C#とパフォーマンス向上(後編)―― 予定・検討中の5つの新機構」でも少し触れていて被る部分もあるが、あらためてC#の文字列処理について説明する。
C#のstring型
C#の文字列はUTF-16を前提としている。char型は2Bytesの整数で、string型はその配列に近い構造をしている。
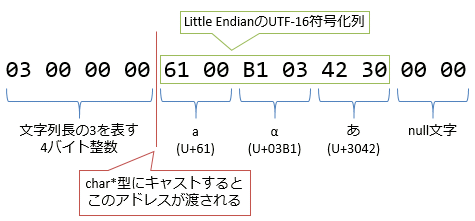
もう少し正確な言い方をすると、string型は、COMのBSTR型と互換で、以下のような構造をしている。
- 先頭に文字列長を4Bytes整数で記録
- 続けて、リトルエンディアンのUTF-16で符号化されたバイト列が並ぶ
- 最後に
null文字(UTF-16なので00 00の2Bytes)を置く
例えば、「aαあ」という3文字であれば、図7のようなメモリレイアウトになっている。この様子はリスト3に示すunsafeなC#コードで確認できる。
|
unsafe static void WriteLayout(string s)
{
fixed (char* ps = s)
{
byte* p = (byte*)ps;
for (int i = -4; i < (s.Length + 1) * 2; i++)
{
var b = *(p + i);
Console.Write(b.ToString("X2"));
}
}
}
|
BSTR型自体も、C言語のnull終端文字列との互換性を持った形式になっている。本来、文字列長を持っていれば文字列末尾にnull文字を付与する必要はないのだが、C言語で書かれたプログラムに対してポインター渡しができるように、わざわざnull文字を付けている。文字列が入っている場所を先頭(char*へのキャストで返す場所)扱いにして、文字列長はそれよりも手前に置いているのも同様の理由である。
string型がBSTR型と同じ構造になっている(結果的に、C言語のnull終端文字列とも互換になっている)ため、C#からNativeコードを呼び出す際のコストはかなり抑えられている。Nativeコード側がUTF-16になっている場合には、変換処理は不要で、ポインターを直接渡すことができる。
string型の問題点
WindowsのAPIは多くが文字列をUTF-16で扱っていて、前節の通り、C#のstring型との相互運用は低コストで行える。従って、Windowsアプリ開発がC#の最大用途だったころなら大きな問題なく使えていた。
しかし、現在は.NET Coreがあり、クロスプラットフォームでのWeb開発でのパフォーマンスが求められている。Web開発を想定すると、図8に示すような点が問題になり始めた。
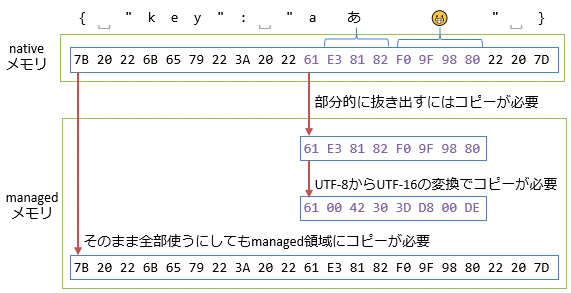
WebではASCIIもしくはUTF-8を使って文字列を送受信することが多い。内部的にUTF-16になっているstring型への変換はそれだけで高コストである。
また、BSTR型やnull終端文字列との互換性のために前後に余計なメモリ領域が必要で、C#のstring型は、メモリ領域の一部分だけを参照して文字列扱いすることができない。部分的にコピーして抜き出す必要があり、新規メモリ確保のコストがかかる。
さらに、C#のstring型は、データがManagedメモリ領域に置かれている必要がある。Nativeコードで書かれた通信層のNativeメモリ領域にあるデータを直接参照して文字列処理することができず、たとえ元からBSTR型やnull終端文字列になっていたとしても、Managedメモリ用域へのコピーが必要になる。
そこで、今求められているのは、以下のような機能である。
- Nativeメモリ領域を直接参照する機能
- メモリ領域の一部分だけを抜き出して参照する機能
- 直接UTF-8を処理する機能
Span<T>
これらの要件を実現するため、新しいライブラリの実装が始まっている。まず、前節の要件のうち、Nativeメモリ領域の直接参照と、一部分を抜き出しての参照の2点を実現するのがSpan<T>構造体だ。説明に必要な部分を抜き出すと、リスト4に示すような構造体になっている。
|
public struct Span<T>
{
// 配列、もしくは、ポインター(スタック領域やNativeメモリ領域を含む)を扱える
public Span(T[] array, int index, int length)
public unsafe Span(void* memory, int length)
// 配列と同じように操作できる
public int Length { get; }
public ref T[int index] { get; }
// 一部分を抜き出して使える
public Span<T> Slice(int index, int length);
}
|
このSpan<T>構造体がリリースされれば、さまざまな用途でパフォーマンス向上が期待できるだろう。ただ、現状はまだ試験運用の段階で、リリースはまだ先になりそうだ。少なくとも、C# 7と同時期にはリリースされない。
オープンソースで開発されているので中身をのぞくことはできるが、このSpan<T>構造体はビルドに少し複雑な手順が必要で、自分でソースコードからビルドするのは少々骨が折れるだろう。
というのも、本当に効率よくSpan<T>構造体を実現しようと思うと「参照フィールド」が必要になる。C#で参照というと、C# 6以前であれば参照引数のみ、C# 7でも参照戻り値と参照ローカル変数の追加のみで、現状の.NETランタイムではフィールドとして参照を持つ安全な手段がない。理想的なパフォーマンスを得るためにはランタイム自体の改修が必要だし、現状のランタイムで動かすための妥協的な実装も必要になる。その妥協的な実装ですら、C#では表現できないコードをILアセンブラーで記述している。
一応、デイリービルドのNuGetパッケージが公開されているので、現時点での実装を試してみたければこのNuGetパッケージを参照するといいだろう。
Utf8String
Span<T>構造体と、その読み取り専用バージョンであるReadOnlySpan<T>構造体を使って、UTF-8を直接読み書きするためのライブラリも整備中だ。コードポイント単位でSpanに対して読み書きするのがUtf8Encoderクラスで、文字列として読み込むのがUtf8String構造体だ。
Span<T>構造体がリリースされない以上、それに依存しているUtf8String構造体のリリースも当分先の話になる。こちらも、デイリービルドのNuGetパッケージを試してみることはできる。
Utf8String型の利用例をリスト5に示そう。この例の通り、Utf8String型であれば、byte配列を直接参照して、メモリ確保なしで文字列を読み込める。ただし、可変長文字コードである性質上、インデクサーを使った「n文字目の取得」はできない。
|
var utf8RawData = new byte[] { 0x7B, 0x20, 0x22, 0x6B, 0x65, 0x79, 0x22, 0x3A, 0x20, 0x22, 0x61, 0xE3, 0x81, 0x82, 0xF0, 0x9F, 0x98, 0x80, 0x22, 0x20, 0x7D };
var utf16RawData = new char[] { '{', ' ', '"', 'k', 'e', 'y', '"', ':', ' ', '"', 'a', 'あ', (char)0xD83D, (char)0xDE00, '"', ' ', '}' };
// string型
{
// UTF-8 → UTF-16の変換でメモリ確保が必要
var s1 = System.Text.Encoding.UTF8.GetString(utf8RawData);
// string型はchar[]を受け取る場合でも、内部でコピーを作るのでメモリ確保発生
var s2 = new string(utf16RawData);
// string.Substringもコピー発生
var sub = s1.Substring(10, 4);
}
// Utf8String型
{
// メモリ確保しない実装
var s = new Utf8String(utf8RawData);
// インデックスでの文字取得はできない。s[0]はByte単位のアクセスになる
// コードポイントの取り出しにはCodePointsを使う
// foreachも全て構造体で展開されるのでメモリ確保不要
foreach (var c in s.CodePoints) ;
// Substringもコピー不要な実装になっている
var sub = s.Substring(10, 8);
foreach (var c in sub.CodePoints) ;
}
|
また、この例からもう一つ問題点が分かる。元データ(リスト5のutf8RawDataオブジェクトやutf16RawDataオブジェクト)がbyte配列になるため、どういう文字列になっているのか全く分からない。ファイルやネットワークからデータを受け取ってUtf8String構造体を作る場合にはこれでも問題はないが、ソースコード中にリテラルを埋め込みたい場合などで困る。Utf8String型を実用化するためには、C#にも、文字列リテラルから直接Utf8Stringオブジェクトを作る言語機能などが必要になるだろう。
ちなみに、このUtf8String型は、現状のstring型を置き換えるものではない。前述の通り、UTF-8とUTF-16にはそれぞれに利点・欠点の両方があるし、リスト6に示すように、データ書き換えの影響範囲がstring型とは異なっている。string型は安全性・生産性を優先、Utf8String型はパフォーマンス優先になっている。
|
// string型
{
// 内部でコピーしているので…
var s1 = new string(utf16RawData);
var s2 = new string(utf16RawData);
// 元データを書き換えても
utf16RawData[0] = '[';
utf16RawData[16] = ']';
// 影響は出ない
Console.WriteLine(s1); // { "key": "aあ😀" }
Console.WriteLine(s2); // { "key": "aあ😀" }
}
// Utf8String型
{
// データを共有しているので…
var s1 = new Utf8String(utf8RawData);
var s2 = new Utf8String(utf8RawData);
// 元データを書き換えると
utf8RawData[10] = 98;
utf8RawData[11] = 227;
utf8RawData[12] = 129;
utf8RawData[13] = 132;
utf8RawData[14] = 240;
utf8RawData[15] = 159;
utf8RawData[16] = 144;
utf8RawData[17] = 136;
// 影響がある
Console.WriteLine(s1); // { "key": "bい🐈" }
Console.WriteLine(s2); // { "key": "bい🐈" }
Console.WriteLine(s1.Substring(10, 8)); // bい🐈
}
|
Compact string
前節の通り、Utf8String型は既存のstring型を置き換えるものではない。また、本来はUtf8String型の方が適しているようなプログラムであっても、今から置き換え作業をするのは骨が折れるだろう。そこで、既存のstring型の効率化はできないかという話も出てくる。
これにも1つ案が出ている。Latin-1なByte配列と、UTF-16な2Bytesのデータ列を切り替えることで、Latin-1だけを含む文字列の処理を効率化する手法である。この案はCompact stringと呼ばれている。もともとはOpenJDKに対して出ている案だが、文字列に関して似た事情を持つ.NETに対しても適用できるはずで、実際に同様の提案が出されている。
前編のUnicodeの説明の中で話したが、Unicodeは、コードポイントとしてはLatin-1の上位互換である。Latin-1中の文字は、全て同じコードポイントでUnicodeに含まれている。リスト7に示すように、Latin-1で符号化されたバイト列と、UTF-16で符号化されたバイト列は、1Byteずつ読むべきか2Bytesずつ読むべきかだけの差となる。
|
var s = "Latin-1, abc àèì";
byte[] latin1 = Encoding.GetEncoding(1252).GetBytes(s); // Latin-1
byte[] utf16 = Encoding.Unicode.GetBytes(s); // UTF-16
for (int i = 0; i < latin1.Length; i++)
{
var x = latin1[i];
var y = utf16[2 * i];
// Latin-1とUTF-16の差は、バイト数の差だけ
// UTF-16の方を1Byte飛ばしで読めば、必ず同じ値が入っている
if (x != y) throw new InvalidOperationException(); // ここは絶対に通らない
}
|
従って、全ての文字がLatin-1に収まる範囲(コードポイントが0xFF以下)であれば1Byteずつ、そうでなければ2Bytesずつ読み出すようなフラグを持てば、メモリの無駄なくLatin-1(ASCIIを含む)文字列を読み書きできる。例えば、リスト8に示すような処理を掛ければいい。
|
/// <summary>
/// byte配列から、
/// 2Bytesずつushortとして読み出すか、
/// 1Byteずつbyteとして読み出すかを切り替えるラッパー型
/// </summary>
public struct ArrayAccessor
{
private bool _isWideChar;
private readonly byte[] _data;
public ArrayAccessor(bool isWideChar, byte[] data)
{
_isWideChar = isWideChar;
_data = data;
}
public unsafe ushort this[int index]
{
get
{
if (_isWideChar)
{
fixed (byte* pb = _data)
{
ushort* p = (ushort*)pb;
return p[index];
}
}
else return _data[index];
}
}
public int Length => _isWideChar ? _data.Length / 2 : _data.Length;
}
|
このCompact stringの案は、string型の内部実装に関するもので、やろうと思えばstring型のAPI(publicなメソッドやプロパティ)を変更せずに採用できる。Javaでこの案が出ている(このままいけばJDK 9で採用)のも、API的な変更なしで効率化できる期待があるからである。
ただし、C#のstring型に対してこの案を適用しようとすると1つ大きな課題がある。前述の通り、C#のstring型はBSTR型互換な形式になっていて、この形式を前提として、Nativeコード呼び出しの最適化が掛かっている。この意味では、たとえ内部実装的な変更であっても、既存のコードを壊す可能性があるため、慎重に検討する必要がありそうだ。
ちなみに、リスト8のような処理を現状のC#で書こうと思うとfixedステートメント(それなりに負担がある)が必要で、あまりよいパフォーマンスが出ない。string型はNative実装なので問題になることはないが、C#で同様の処理を効率よく行うためには、前述のSpan<T>構造体がここでも必要になる。
余談になるが、SwiftのString型はこのLatin-1/UTF-16切り替え式のデータ構造になっている。
ソースコード中で識別子に使える文字
ソースコードのコンパイルでも、最初に行われるのは文字列処理で、文字コードの影響を受ける。そして、Unicodeの普及以降に生まれたプログラミング言語では、ほとんどのものがUnicodeを前提に言語仕様を作っている。
Unicode前提の仕様の一つが識別子に使える文字の定義だ。通常はUnicodeの文字カテゴリに基づいて、識別子に使えるかどうかを決めている。Java、C#、Goなどでは、大まかにいうと「Letter*1のみ」という判定になっている。具体的な仕様は以下の通りだ。
- Java: 「Java Language Specification: Chapter 3. Lexical Structure: JavaLetter」*2
- C#: 「C#言語仕様: 2.4.2 識別子: letter-character」
- Go: 「The Go Programming Language Specification: unicode_letter」
例えばC#では「クラス Lu、Ll、Lt、Lm、Lo、または Nl の Unicode 文字」などと書かれているが、これが大まかにLetterカテゴリを表している。
一方で、制限が緩いものもあって、Swiftはたいていの文字を識別子として使える。むしろ、一部の記号などを除外するような仕様*3になっているが、これもUnicodeのコードポイントを基に仕様を定めている。
- *1 ラテンアルファベットや仮名漢字など、言葉を書き表すのに使う文字。
- *2 Javaの場合は「
Character.isJavaIdentifierStartメソッドがtrueを返す文字」という定義になっているが、このメソッドの仕様まで追うと、Unicode文字カテゴリを基準にした判定になっている。 - *3 とはいえ、除外の基準はよく分からず、数式記号や不可視文字も含めて大半の文字が識別子として使える。
ソースコードの文字コード判定
文字集合としてUnicodeが採用されているということと、ソースコードに使う符号化方式とはまた別の問題である。Goなどの新しめの言語であれば、ソースコードはUTF-8で保存されていることを前提とするものも多い。しかし、1990年代から2000年代初頭の言語であるJavaやC#ではそうはいかない。オプション指定がない場合、OSの既定の文字コードを使うようになっている。
C#の場合は少し複雑で、以下のような挙動になっている。
- BOM*4が入っていれば自動判定してUTF-8として読み込む
- BOMがない場合で、OSの既定の文字コードを取得できた場合はそれを使う
- .NET Coreなど、OSの既定の文字コードも取得できなかった場合はLatin-1を使う
要するに、日本語Windows環境であれば、何もしなければ自動的にShift_JIS(正確にはその拡張であるMS932)になる。ただし、現在のVisual StudioやXamarin Studio上でC#ソースコードを新規作成すると、BOM付きUTF-8で保存される。これらを使った開発であれば、C#のソースコードはUTF-8だと思って差し支えないだろう*5。
この、「BOMが入っていればUTF-8扱い」という挙動は、過去の資産が非常に多いWindows特有の事情でもある。他の環境ではBOM付きUTF-8を正しく読み込めない場合もあり、たびたび問題となる。例えば、JavaコンパイラーはBOM付きUTF-8のソースコードを読むとコンパイルエラーを起こす。
一方、OSの既定の文字コードを使うというのは、クロスプラットフォーム対応で面倒を引き起こす。C#コンパイラーを.NET Core対応するに当たって、いったん、OSの既定の文字コードを調べず、BOMが入っていなければ即、Latin-1扱いする対応が入ったことがある。この対応で問題が起こったことは「オピニオンコラム:岩永信之(1): オープンソースのC#/Roslynプロジェクトで見たこと、感じた教訓」で説明した通りである。その後、既定の文字コードを調べる処理は復活したが、既定の文字コードが取得できなかった場合にLatin-1を使うようにする対応は現在でも残っている。
- *4 Byte Order Mark: UTF-16(2バイト文字)やUTF-32(4バイト文字)のエンディアンがどうなっているかを記録するための文字。
U+FEFFというコードポイントになっていて、FE FFの順で入っていればビッグエンディアン、FF FEの順で入っていればリトルエンディアンということになる。エンディアンだけでなく、UTF-8であってもこれを符号化したEF BB BFの3バイトを記録することで、文字コードの判別に使える。 - *5 「オピニオンコラム:岩永信之(1): オープンソースのC#/Roslynプロジェクトで見たこと、感じた教訓」で話したが、最初期のVisual Studioは既定の文字コード(Shift_JISなど)でC#ソースコードを保存していた。この時代のソースコードが残っていた場合、問題を起こすかもしれない。
サロゲートペア
ソースコードの文字コードがらみでは、サロゲートペアをどう扱うという問題もある。実は、C#コンパイラーはサロゲートペアになっている文字の文字カテゴリを正しく判定しない。C#では、リスト9に示すように、char型(UTF-16)単位でのカテゴリ判定と、コードポイント単位でのカテゴリ判定用の両方のメソッドを持っているが、C#コンパイラーは前者しか使っていないため、サロゲートペアは一律全て、識別子として使えなくなっている。
|
var s = "𩸽";
// 「𩸽」はサロゲートペアになっているので、charとしては2文字になる
foreach (var c in s)
{
// Surrogateが2回表示される
Console.WriteLine(char.GetUnicodeCategory(c));
}
// stringを受け取るGetUnicodeCategoryオーバーロードなら、
// サロゲートペアな文字もコードポイントにデコードして正しくカテゴリ判定できる
// OtherLetter(漢字のカテゴリ)が表示される
Console.WriteLine(char.GetUnicodeCategory(s, 0));
|
他の言語の状況でいうと、最初からUTF-8を前提としているGoは当然として、C#より古いJavaですら、サロゲートペアを正しく識別子として受け付ける(当然、文字カテゴリは見る。「𩸽」(U+29E3D)であればLetterなので使えるが、「😀」(U+1F600)は記号なので使えない)。この点では、C#は少し古い作りで取り残されている。
言語仕様上は「Letterならば識別子に使える」といっているC#で、これは問題だろう。ただし、C# 5.0までであれば、実は、仕様書には「Unicode 3.0に従う」と書かれていた。サロゲートペアという概念自体はあった(Unicode 2.0で規定)が、実際にサロゲートペアを使ったコードポイントは1文字もなかったころのことである(入ったのはUnicode 3.1以降)。
しかし、C# 6以降、“depend on the underlying platform for their Unicode behavior”(Unicodeの振る舞いに関してプラットフォームの挙動による)という話になった。現在ではサロゲートペアを受け付けないことはバグとして認識されている。
もちろん、この手の文字を本当に使いたいかという問題はある。ただでさえ、通常、識別子として非ASCII文字を使う人は少なく、日本語や中国語の識別子すらめったに見かけるものではない。まして、サロゲートペア、かつ、日常で使いそうなLetterの文字というとほとんどない。結果的に、バグと認識されているからといって、修正作業に対する優先度はかなり低い状態になっている。
筆者個人の意見としては、C#もいつかはサロゲートペアに正しく対応すべきだが、タイミングに関してはUtf8String型などの整備が終わった後でも構わないのではないかと思っている。
まとめ
Unicodeの歴史に引きずられる形ではあるが、C#では、文字列処理がなかなか面倒になっている。特に、C#の開発開始がUnicode登場初期(C# 1.0リリース時点でもUnicode 3.0)のころだったこともあり、サロゲートペアを前提にしていない部分が多い。
例えば、C#ソースコード中で、識別子に使える文字はUnicodeの文字カテゴリを基に、Letterであることが求められている。しかし、現在のC#コンパイラーはサロゲートペアを受け付けず、この領域にある文字はLetterであっても使えない状態になっている。これはC#コンパイラーの既知のバグである。
また、「オピニオンコラム:岩永信之(7): 次期C#とパフォーマンス向上(後編)―― 予定・検討中の5つの新機構」でも話したように、今、パフォーマンス向上のための機能がC#の大きなテーマの一つとなっている。その一環として、ASCIIやUTF-8で符号化された文字列を効率よく処理するためのライブラリや言語機能の整備が求められている。
そのために出ている案として、本稿ではUtf8String型やCompact stringというものを紹介した。ただし、これらの実装にもいくつか課題があり、リリースされるのはまだもう少し先の話になりそうである。
1. Unicodeとは? その歴史と進化、開発者向け基礎知識
今やソフトウェアでの文字表現に広く使われているUnicode。その登場の背景としてASCIIやShift_JISの概要と課題を説明し、それを解決したUnicodeの特徴や、「UTF-16か、UTF-8か」の選択指針を解説する。
2. 【現在、表示中】≫ Unicodeと、C#での文字列の扱い
進化の過程で煩雑な文字コード体系になっているUnicodeは、プログラミングでの取り扱いが面倒だ。C#とUnicodeの関係はどうなっているのか? C#が抱える課題とその解決策について見てみよう。