
C#と文字コード(前編)
Unicodeとは? その歴史と進化、開発者向け基礎知識
今やソフトウェアでの文字表現に広く使われているUnicode。その登場の背景としてASCIIやShift_JISの概要と課題を説明し、それを解決したUnicodeの特徴や、「UTF-16か、UTF-8か」の選択指針を解説する。
「オピニオンコラム:岩永信之」のスピンオフ記事である本連載(前編・後編の全2回)では、C#における文字コード関連の話をしたい。文字コードというと、現在ではすっかりUTF-8がデファクトスタンダードとなっているが、Unicode自体も複雑で、かつ、C#はUnicode以前の歴史も引きずっているため、なかなか分かりにくい状況になっている。
そこで今回はまず、Unicode登場前後の歴史なども含めた文字コード自体のおさらいをする。そして次回で、他のプログラミング言語の状況なども交えつつC#の文字列処理に関する話をしていきたい。
Unicodeとは
最初に、Unicodeの概要や、Unicodeで使う用語について説明しておこう。Unicodeは全世界共通で使えるように、世界中の文字を収録する文字コード規格である。現在、すでに「定番」となっていて、過去の資産の活用以外の目的では、他の文字コードを好んで使うことはあまりないだろう(もちろん過去の資産は非常に多く、Unicodeに一本化される未来は今後もしばらく来ないだろう)。
ただし、Unicodeにもいくつかの異なる符号化方式が存在する。このことを説明するために、表1にいくつかの文字の例を挙げる。上の行から、ローマンアルファベット(a)、ギリシャ文字(α)、ひらがな(あ)、絵文字(😀)である。
| 文字 | コードポイント | UTF-32 | UTF-16 | UTF-8 |
|---|---|---|---|---|
| a | 61 | 61 00 00 00 | 61 00 | 61 |
| α | 3B1 | B1 03 00 00 | B1 03 | CE B1 |
| あ | 3042 | 42 30 00 00 | 42 30 | E3 81 82 |
| 😀 | 1F600 | 00 F6 01 00 | 3D D8 00 DE | F0 9F 98 80 |
まず、Unicodeで規定されている文字1つ1つには、最大で21bits(16進数で5~6桁)の数値が割り振られている。この数値をコードポイント(code point: 符号点、符号位置)という。
ちなみに、Unicodeでは、コードポイントの数値で文字を表すための表記として、「U+16進数」という書き方を使う。例えば、「a」であればU+61、「あ」であればU+3042と表記する(以下、文字コードは全て16進数で表記する)。
一方で、この21bitsのコードポイントがそのままテキストファイルに保存されるわけではない。一定のルールでバイト列に符号化することになる。詳細については、後々、Unicodeの歴史を追いつつ説明していくが、おおむね以下の3つを押さえておけばいいだろう(加えてコードポイントがビッグエンディアンで格納されるか、リトルエンディアンで格納されるかも重要になる。が、今回と次回はリトルエンディアンで格納されるものとする)。
- UTF-32: コードポイントをそのまま4Bytesの固定長で記録する
- UTF-16: 2Bytes以下に収まるコードポイントはそのまま2Bytesの整数として記録し、それを超えるものはペア(2×2で4Bytes)を使って記録する
- UTF-8: 1~4Bytesの可変長で記録する
ここで注意が必要なのは、Unicode策定当初にはコードポイントが2Bytes以下で、今でいうUTF-16が2Bytes固定長の文字列になっていたことである。JavaやC#など多くのプログラミング言語で、標準の文字型(char)は2Bytes、文字列型(string)はその配列で表現される。その後、charの2文字分を使って1つのコードポイントを表す必要が生まれたため、stringの持つ文字列長(Length)が、実際のUnicode文字列の長さを表さなくなってしまった。
ただし、コードポイントで数えた長さもあくまで「Unicodeが値を定めている文字」の数である。「ユーザーが文字として認識するもの」の数を数えるにはもう一工夫必要になる。図1に示すように、文字の結合があり得るのだ。
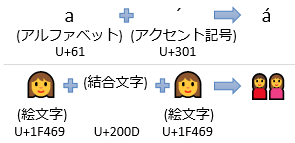
ユーザーは結合結果を1文字と認識する。Unicode的に複数の文字から成るといっても、[backspace]/[delete]キーで半分ずつ消えたり、テキスト選択でバラバラに選択されたりしては困ることになる。この、ユーザーが1文字として認識する単位を書記素(grapheme)といい、書記素を構成する複数のコードポイントを書記素クラスター(grapheme cluster)と呼ぶ。
つまり、一口にUnicodeといっても、以下のような異なる処理単位を考える必要がある。
- 書記素クラスター: ユーザーが文字として認識する単位。フォントレンダリングや文字の削除/選択にはこの単位での処理が必要
- コードポイント: Unicodeが値を定めている文字の単位
- 符号化: 符号化の方式(UTF-16やUTF-8)によって、保存や通信の際に必要となるデータ量が変わる
これらの詳細を話すに当たって、文字コードの歴史を少し追いつつ説明していこう。
Unicode以前
まず、Unicodeの登場までの背景を簡単にまとめておこう。
- ASCIIとの互換性は重要
- Unicode以前の文字コードは国ごとにばらばら
- 同じ文字集合に対して異なる符号化方式があり得る
- 可変長文字コードの処理は面倒
- 必要とされる文字は当初想定よりもだいぶ増える
ASCII
最初に文字コードを標準化したのはアメリカであり、その文字コードはASCII(American Standard Code for Information Interchange)と呼ばれている。各国の文字コードはASCIIをベースに、裁量が認められていた数文字の変更や、ASCIIが使っていない8bits(80以上)のコードポイントに文字を追加したものである。すでにASCIIコードを前提に書かれたプログラムが多く、ASCIIとの互換性は非常に重要だった。
SMTPやHTTPなど、主要な通信プロトコルがASCIIを前提としている。さすがに「古臭い」とされ、HTTP/2(バイナリやUTF-8を使う)など置き換えを狙ったプロトコルも生まれて順調にシェアを伸ばしてはいるが、完全に移行を終えるにはまだまだ時間がかかるだろう。
国ごとにばらばら
Unicode登場以前は、国ごと・言語ごとにばらばらに文字コードを定めていた。文字数の少ない西欧のラテン文字圏では、1Byteの共通の文字コードを使っていたが、ギリシャ語やアラビア語を使う国々ではそれぞれ独自の文字コードを持つ必要があった。まして、文字数が多い日本語や中国語はいわずもがなである。
ちなみに、最も基本となる文字コードはアメリカの本家ASCII(US-ASCIIと呼ばれたりする)だが、次いで使われるのが、US-ASCIIに西欧各国の文字を追加したLatin-1という1Byte文字コードである(表2)。前半(7F以下)の文字がUS-ASCIIと完全互換であることと、西欧の広い範囲で使えたことから、1Byte文字コードの代表格となっている。
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NUL | SOH | STX | ETX | EOT | ENQ | ACK | BEL | BS | HT | LF | VT | FF | CR | SO | SI |
| 1 | DLE | DC1 | DC2 | DC3 | DC4 | NAK | SYN | ETB | CAN | EM | SUM | ESC | FS | GS | RS | US |
| 2 | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / | |
| 3 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4 | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5 | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6 | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7 | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | DEL |
| 8 | 未使用 | |||||||||||||||
| 9 | ||||||||||||||||
| A | NBSP | ¡ | ¢ | £ | ¤ | ¥ | ¦ | § | ¨ | © | ª | « | ¬ | SHY | ® | ¯ |
| B | ° | ± | ² | ³ | ´ | µ | ¶ | · | ¸ | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
| C | À | Á | Â | Ã | Ä | Å | Æ | Ç | È | É | Ê | Ë | Ì | Í | Î | Ï |
| D | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| E | à | á | â | ã | ä | å | æ | ç | è | é | ê | ë | ì | í | î | ï |
| F | ð | ñ | ò | ó | ô | õ | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
20(=2行0列目)は「半角スペース(SP文字)」を意味する。また、A0(=A行0列目)は「ノーブレークスペース(NBSP文字)」を意味する。
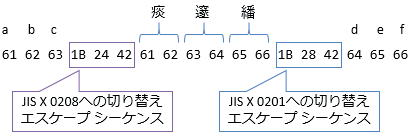
当初、言語を混在させたい場合には、エスケープシーケンス(=ESC文字(1B)に続く数文字で何らかの制御を行う手法)を使って文字コードを切り替えて使う想定だった。実際、日本語でいうと俗にいう「JISコード」(正式にはISO-2022-JPという規格になる)がそれに当たる。ASCII(正確にはその日本版であるJIS X 0201)でラテン文字を入力したければ1B 28 42(ESC ( B)という3文字で、日本語文字コード(JIS X 0208と呼ばれている)で日本語文字を入力したければ1B 24 42(ESC $ B)という3文字で、文字コードを切り替える。
JISコードの実例を図2に示そう。「abc痰邃繙def」という文字列を符号化した例である。英語は1Byte、日本語は2Bytesで、その間1Bから始まる3文字の切り替え用コードが挟まっている。
文字集合と符号化方式
図2の例を見ての通り、JIS X 0201の部分とJIS X 0208の部分で全く同じ数値が現れる。一部分だけを切り出した場合、どちらの文字コードなのか分からず、正しく文字を認識できない可能性が高い。
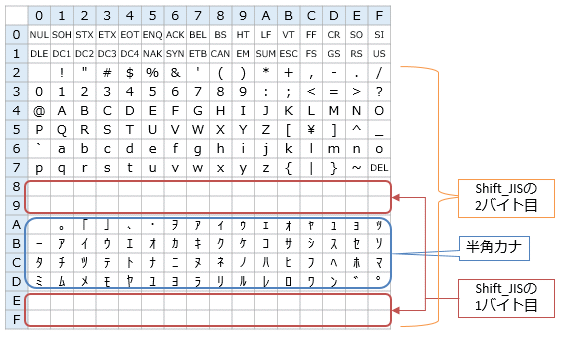
そこで、JIS X 0201が使っていない領域に、JIS X 0208が定める文字を収めることが考えられた。そうした方式の一つがいわゆるShift_JISである。Shift_JISは図3に示すようなコード配置になるように、JIS X 0208を組み替えたものである。これとは別に、EUC-JPという方式もある。
この結果として、同じ文字を異なる符号で表現する方式が生まれた。ISO-2022-JP、Shift_JIS、および、EUC-JPは、同じ文字を異なる符号化方式で記録している。このことから言えることとして、文字コードは以下の2つの概念を分けて考える必要がある。
- 文字集合: どういう文字にコードポイントを与えるか、コードポイントの数値の範囲をどうするか
- JIS X 0208は文字集合を規定する規格 - 符号化方式: 文字集合をどういうバイト列で表現するか
- ISO-2022-JP、Shift_JIS、EUC-JPはいずれも、JIS X 0201(ASCII)とJIS X 0208という2つの文字集合を記録するための符号化方式
可変長文字コード
ISO-2022-JP、Shift_JIS、EUC-JPのどの方式にしろ、ASCIIとの混在の結果、1~2Bytesの可変長文字コードになっている。その結果、文字数カウントや検索、置換などの文字列処理はそれなりに面倒になっていた。
文字は増える
JIS X 0208を策定した当初は、コンピューターのハードウェア的な制約が大きく、文字数を絞らざるを得なかった。何千文字もの漢字を表示するにはフォントだけでも、当時の基準でいうとかなりの大容量が必要になるからだ。
そこで、JIS X 0208では漢字に優先度を付けて、日常でよく使われる漢字を「第1水準漢字」(2965文字)、人名や地名のみで使う珍しい漢字や旧字体を「第2水準漢字」(3384文字)に分けた。もちろん、第2水準でもかなり絞った結果である。「これでは足りない」と各ハードウェアメーカーがそれぞれ独自拡張文字を用意したくらいである。
まして、「収録できる文字数に余裕がある」といわれると、いくらでも文字は増えるものである。
以上のような背景の中、Unicodeが作られることになる。
Unicode
前節で説明した通り、国ごとに文字コードを定めた上でエスケープシーケンスを使って切り替える方式は制約もあったので、結局、文字のやりとりが全世界的にこの方式に統一されることはなかった。そうなると、国をまたいだ文字のやりとりのために、全世界の文字を統一的に扱える単一の文字コードが新たに求められた。それがUnicodeである。1980年代後半から検討が始まり、1991年にバージョン1.0が制定された。
制定当初の計画では、Unicodeは2Bytes固定の文字コードだった。Shift_JISなどの経験から、可変長文字コードの扱いがかなり面倒になることは分かっていたし、2Bytes(最大で65536文字)あれば世界中の文字を納められると思われていた。
実際、日本、中国、韓国の文字コードが含む漢字を、字形が近く意味が同じものを全て統合するなら、2万文字程度になることが当時分かっていた。統合のミス(意味が違うものを統合してしまったり、その逆であったり)などの問題も何文字か出てはいるが、何とか統合でき、無事に2Bytes固定の文字コードが完成した。
これ以降、文字型が2Bytes整数、文字列型がその配列になっているプログラミング言語が現れ始める。JavaやC#が典型例で、これらの文字型は2Bytesになっている。既存の、文字型が1Byteのプログラミング言語にも、2Bytesの「ワイド文字」が追加され始めた。
ASCIIとの互換性
既存資産を考えると、ASCIIとの互換性は必須である。Unicodeでももちろんそれを考慮して、1Byte領域(00~FF)のコードポイントが全てLatin-1と同じになっている。しかし、2Bytes固定長にするなら、図4に示すように00を挟む必要があって、ASCII文字列をそのまま扱うことができない。
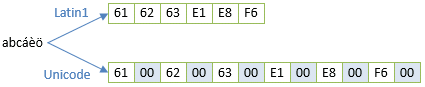
実際、現在のJavaやC#(いずれも内部的にUnicodeを利用)では、Latin-1で符号化された文字列を読み書きしたければ、00を挟んだり削ったりする符号化処理が必要になる。より細かくいうと以下のような処理が必要になり、負担はそれなりに大きい。
- 元のLatin-1文字列が入ったバイト列の2倍の長さのメモリを確保する
- 1文字1文字、
00を挟みつつ文字をコピーしていく
前述の通り、ASCIIとの互換性は非常に重要である。そこで、やはり、UnicodeでもASCII互換な符号化方式が必要とされた。それがUTF-8である。UTF-8ではコードポイントを、表3に示すルールで符号化する。
| ビット数 | 最小値 | 最大値 | 変換方法 | bit パターン | ||||
|---|---|---|---|---|---|---|---|---|
| 元コードポイント | 1バイト目 | 2バイト目 | 3バイト目 | 4バイト目 | ||||
| 7 | U+0000 | U+007F | そのまま | xxxxxxx | 0xxxxxxx | |||
| 11 | U+0080 | U+07FF | 2バイト化 | xxxxxxxxxxx | 110xxxxx | 10xxxxxx | ||
| 16 | U+0800 | U+FFFF | 3バイト化 | xxxxxxxxxxxxxxxx | 1110xxxx | 10xxxxxx | 10xxxxxx | |
| 21 | U+10000 | U+1FFFFF | 4バイト化 | xxxxxxxxxxxxxxxxxxxxx | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
後述するサロゲートペアの仕様が入るまではコードポイントは16bitsが上限で、UTF-8は1~3Bytesの可変長コードだった。現在は、Unicodeのコードポイントが21bitsに拡張されていて、UTF-8も最大で4Bytesの可変長コードになっている。
ちなみに、符号化方式としては最大で31bitsのコードポイントを6Bytesに符号化するルールまで決まっている。現状は21bitsで十分であり、5Bytes・6Bytesになる文字は存在しない。
2バイト目以降の値は常に10から始まるbitパターンになっていることにも注目してほしい。1Byte文字や、多バイト文字の1バイト目とは絶対に同じ値を取らない。文字列の途中を抜き出した場合でも、すぐに文字の区切りを判断できるようになっている。
コードポイントが7bits以下であれば、そのままの値を1Byteに符号化する。Unicodeのコードポイントで、7bits以下のものはASCIIそのものなので、UTF-8はASCII互換となっている(一方で、Latin-1拡張の8bits文字(「á」などの文字)は2Bytesに符号化されてしまう。従って、Latin-1との互換性は得られない)。
これで、ASCII文字は1Byteで符号化できるようになった。ASCII圏の人々にとっては、テキストファイルのサイズが倍に膨らまずに済むようになる。一方、カナ漢字はU+8000以上のコードポイントになっていて、UTF-8では3Bytes文字を使って表現される。日本語のテキストはカナ漢字が2BytesになるShift_JISやUTF-16と比べて1.5倍程度大きくなってしまう。
21ビット化
Unicodeが当初2Bytes(=16bits)あれば十分と思われていた理由は、Unicodeに収める漢字の数は日中韓を合わせても2万文字程度で済み、2Bytesあればまだ3万文字程度の余裕があると思われていたからである。このうち、日本の漢字は第1水準、第2水準合わせて6000文字程度だ。しかし、JISコードの説明で話した通り、これはコンピューターの性能的な理由で絞った数であり、もし「入れてもいい」といわれればもっと増えるものである。「3万文字余裕がある」といわれれば一気に増えるのだ。
また、文字を追加するに当たっては、IT技術者だけでなく、言語学者にも参画してもらった。するともちろん、技術者が把握していないマイナー言語の文字が次々と出てくるわけである。それに、現在は話者が残っていなくても、文献に残っているものなら古語の文字も入れたいという話も出てくる。当然、3万文字の余裕など一瞬にしてなくなった。
そこで、「Unicode 1.1の時点でまだ使っていない領域を、2文字1組にして、最大で21bitsの1つのコードポイントを表現するために使う」というルールを定めた。これをサロゲートペア(surrogate pair: 代理対)という。具体的には、表4に示すようなルールになっている。
| 範囲 | 変換方法 | bit パターン | 備考 | ||
|---|---|---|---|---|---|
| 元コードポイント | 1文字目 | 2文字目 | |||
| U+0000~U+D7FF, U+E000~U+FFFF |
そのまま | xxxxxxxxxxxxxx | xxxxxxxxxxxxxx | ||
| U+10000以上 | 2文字使う | uuuuuxxxxxxxxxxxxxxxx | 110110wwwwxxxxxx | 110111xxxxxxxxxx | wwww = |
これ以前、特にUTF-8の案が出るまで、Unicodeはコードポイントをそのまま2Bytesで記録するつもりだった。つまり、単にUnicodeというと文字集合だけでなく、符号化方式も指していた。
サロゲートペアの追加によりこの前提が崩れたわけである。文字集合としては21bitsの数値となり、文字によっては1文字4Bytesに符号化して使う状態になった。この符号化方式は、現在ではUTF-16と呼ばれているが、いまだに単にUnicodeと呼ぶ場合もある。
もちろん、21bitsに広がったコードポイントをそのまま記録する方式も用意された。といっても、21bitsでは半端なので、きりよく1文字を4Bytesで記録する。これをUTF-32と呼ぶ。
ちなみに、サロゲートペア導入前からある2Bytesのコードポイント領域を基本多言語面(basic multilingual plane、BMP)、サロゲートペアによって追加されるU+10000以上のコードポイント領域を追加面(supplementary planes)と呼ぶこともある。追加面は、「planes」と複数形になっていることから分かる通り、何面かに分けて運用する。1面あたり最大65536文字(2Bytes)で、表4におけるuuuuuの部分が面の番号、xxxxxxxxxxxxxxxxの部分が面内の文字を表している。
UTF-16か、UTF-8か
もともとは2Bytes固定であることが非常に大きなメリットとなっていたUnicode(現在でいうUTF-16)だが、サロゲートペアの導入によって、結局、可変長文字コードになってしまった。どの道、可変長なのであれば、最初からASCIIとの互換性があるUTF-8の方を使いたくなる。
とはいえ、コードポイントを取り出すためのデコード処理はUTF-16の方がだいぶ軽い。UTF-16とUTF-8のデコード処理の例(C#)をそれぞれリスト1、リスト2に示す(エラー処理は省略している)。以下の2つの理由から、UTF-16の方が数割~2倍程度高速にコードポイントを取り出すことができる。
- 一般的な文章内におけるサロゲートペアの登場頻度はそこまで高くはない。UTF-16では大部分の文字がそのままコードポイントになっていて素通しできる
- UTF-16でサロゲートペアになっている文字は、UTF-8では4Bytesになっている。UTF-16の2文字から1つのコードポイントを得る処理の方が、UTF-8の4Bytesをデコードする処理よりも軽い*1
- *1 ただし、これはリトルエンディアンで、文字を構成する要素の順序入れ替えが不要な場合の話。ビッグエンディアンなUTF-16を.NETで処理しようとしたり、リトルエンディアンなものをJavaで処理しようとしたりすると、それほどの差は出ないかもしれない。
|
unsafe static (uint codePoint, int count) DecodeUtf16(ushort* p)
{
uint code = p[0];
if ((code & 0b1111_1100_0000_0000) == 0b1101_1000_0000_0000)
{
// サロゲートペア: 絵文字など
code = (code & 0b0011_1111_1111) + 0b0100_0000;
code = (code << 10) | ((uint)p[1] & 0b0011_1111_1111);
return (code, 2);
}
else
{
// 頻度的に大半の文字がこっちに来るはず。値を素通し。
return (code, 1);
}
}
|
|
unsafe static (uint codePoint, int count) DecodeUtf8(byte* p)
{
uint code = p[0];
if (code < 0b1100_0000)
{
// 1Byte: ASCII文字
return (code, 1);
}
if (code < 0b1110_0000)
{
// 2Bytes: 主に欧米の文字
code &= 0b1_1111;
code = (code << 6) | (uint)(p[1] & 0b0011_1111);
return (code, 2);
}
if (code < 0b1111_0000)
{
// 3Bytes: かな漢字など
code &= 0b1111;
code = (code << 6) | (uint)(p[1] & 0b0011_1111);
code = (code << 6) | (uint)(p[2] & 0b0011_1111);
return (code, 3);
}
// 4Bytes: 絵文字など
code &= 0b0111;
code = (code << 6) | (uint)(p[1] & 0b0011_1111);
code = (code << 6) | (uint)(p[2] & 0b0011_1111);
code = (code << 6) | (uint)(p[3] & 0b0011_1111);
return (code, 4);
}
|
ASCIIとの互換性を気にせずに使える場面や、コードポイントを頻繁に読み出したい場合にはUTF-16の方が有利だろう。
また、UTF-16で「サロゲートペアにはあえて対応しない」という選択もあり得る。絵文字などは2文字と数えてしまう、文字のカテゴリー判定も「その他」的な扱いで処理してしまうという割り切りができるのなら、UTF-16はいまだ固定長文字コードとして、デコード処理なしで取り扱える。場面を選ぶが、これで十分な場合もあるだろう。それでよければ、UTF-16はパフォーマンス的にますます有利になる。
逆に、コードポイント単位ではなく、バイト配列のままでの処理で十分であれば、UTF-16のメリットは特になくなる。また、含まれている文字の大部分がASCIIであれば、必要なデータ量がほぼ半分で済むことになり、UTF-8の方が有利になる。
ちなみに、UTF-32であれば固定長にはなるが、さすがに大半の文字が2Bytesで収まる中、全てを4Bytesで表現するのは無駄が多い。また、コードポイントとしては固定長であっても、次節で説明するように、ユーザーが認識する文字の単位としては1コードポイント=1文字とはならず、結局、可変長な処理が必要となる。これらのことから、UTF-32を使いたがる人はあまりいない。
書記素クラスター
Unicodeのコードポイントを割り当てられている文字の中には、単独では意味をなさず、他の文字と結合して使うものがある。冒頭の概要説明でも述べたが、ユーザーはそれぞれの文字ではなく、結合結果を1文字と認識する。この複数のコードポイントで形成される単位を書記素クラスターという。いくつかの例を図5に示す。
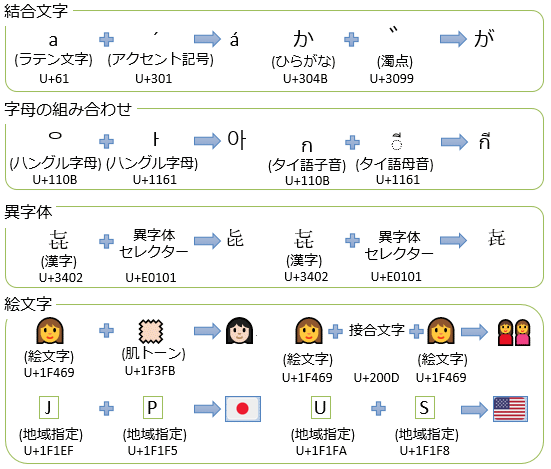
それぞれ以下のようなものである。
- 結合文字: ベースとなる文字(ラテン文字や仮名文字)に印(アクセント記号や濁点)を付けた文字を2つのコードポイントに分けて表現する
- よく使う「á」(U+E1)や「が」(U+304C)などの文字に関しては1つのコードポイントが割り当てられているが、普通は使わない「b́」(U+62 U+0301、「b」に鋭アクセント)や「か゚」(U+304B U+309A、「か」に半濁点)などは結合文字でしか表現できない - 字母の組み合わせ: ハングルやタイ語では、子音・母音ごとにコードポイントが割り当てられているが、通常、これらの子音・母音は単体では使われず、必ず組み合わせた状態で現れる
- 異字体: 漢字の異字体(=同じ文字・同じ意味と見なされるが字形が異なる文字)の表現に、ベースとなる漢字に字形を選択するための文字を付けて表現する。この選択用の文字を異字体セレクター(ideographic variation selector)という
- 絵文字: もともとは日本の携帯電話における独自の文化だったものを国際化した結果として出てきた問題を解決するために、絵文字はかなり複雑な処理を必要とする
- 「顔文字が特定の人種に偏って見える」という問題に対して、顔文字の肌色(skin tone)を変える修飾文字を導入
- 「家族絵文字が男女のペアしかないのは性的少数者への配慮に欠ける」という問題に対して、接合文字(U+200D、zero width joiner、略してZWJ)を使って家族絵文字を構成
- 「少数の国旗に偏るわけにはいかない」という問題に対して、A~Zに相当する地域指定用のコードポイント(regional indicator symbol)を用意して、国名コード(ISO 3166-1)に対応した2文字を使って国・地域を表現
Unicodeではこれらの文字に対して、結合文字の前では切らない、ZWJの前後では切らない、子音の後ろに母音が来ていたら切らないというような、文字区切りのルールを定めている。
ただし、これらのルールや新しい文字は、Unicodeのバージョンアップに伴って随時追加されているわけで、実際にこれらが1文字として描画されるかどうかは環境依存である。OSがそのバージョンによって異なるのはもちろん、フォントによっても1文字で表示できるかどうかが変わる。結合文字などは古くからあり対応しているものも多いが、絵文字に関しては最近の仕様なのもあってかなりばらつきがある。
最後に、書記素、コードポイント、UTF-16、UTF-8のまとめも兼ねて、絵文字の文字コードがどうなるかを図6に示す。
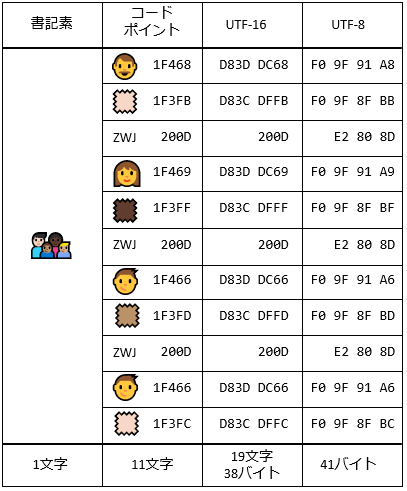
この例で使っている文字は、現状(Unicode 8.0)において最も複雑な絵文字の一つだろう。肌色の異なる4人家族の絵文字で、肌トーン修飾文字や接合文字を含む、11のコードポイントからなる。UTF-8で符号化すると41Bytesにもなるが、見た目上はたった1文字として描画される(Wordでの入力の様子は、次の動画を参照)。
Wordでの入力の様子
■
今回は文字コードの歴史を振り返りながら、Unicodeが登場した経緯、文字集合と符号化方式、Unicodeの拡張などについて見てきた。次回は以上を踏まえて、C#での文字列の扱いがどうなっているのか。どこに課題があるのか、その解決策は何か、といった話をしていこう。
1. 【現在、表示中】≫ Unicodeとは? その歴史と進化、開発者向け基礎知識
今やソフトウェアでの文字表現に広く使われているUnicode。その登場の背景としてASCIIやShift_JISの概要と課題を説明し、それを解決したUnicodeの特徴や、「UTF-16か、UTF-8か」の選択指針を解説する。
2. Unicodeと、C#での文字列の扱い
進化の過程で煩雑な文字コード体系になっているUnicodeは、プログラミングでの取り扱いが面倒だ。C#とUnicodeの関係はどうなっているのか? C#が抱える課題とその解決策について見てみよう。