連載:Intel Perceptual Computing SDK(現:RealSense SDK)入門(5)
無償で簡単にアプリに組み込める「音声認識&音声合成」
マイクに向かってしゃべると音声をテキスト化する「音声認識」や、テキストを音声データに変換する「音声合成」をPC上のアプリで実現したい場合、無償のPerC SDKが便利だ。その開発方法を解説。
最終回として音声認識および音声合成を解説する。この2つを使うことで、音声とテキストを相互に変換できるようになる。
音声認識および音声合成には、それぞれの言語(英語や日本語など)の音声エンジンが必要になる。セットアップ時に音声エンジンのインストール設定があるが、後からでも追加できる。こちらのページから各国語の音声エンジンがダウンロードできるので利用していただきたい。もちろん日本語の音声エンジンもリリースされているので、日本語での音声認識および音声合成も可能だ。
なお、音声認識はSenze3Dだけでなく、ノートパソコンに内蔵されているマイクなど一般的なマイクを利用することもできる。音声合成もテキストを音声データに変換する機能なので、音を出力できるスピーカーがあれば動作させることができる。
本連載のコードは、次の環境での動作を確認している。環境の構築は第3回を参照してほしい。
- Windows 8.1 Pro(64bit版)
- Visual Studio 2012 Express for Windows Desktop
- Intel Perceptual Computing SDK Release7(以下「PerC SDK」とする。現在は「Intel RealSense SDK」)
- OpenCV
音声認識
それでは音声認識から見てみよう。
音声認識は話した声をそのままテキスト(文字列)に変換する機能だ。認識方法には2つあり、1つは単語を指定し、その単語を認識させるコマンドモード、もう1つは話した言葉そのものを認識するディクテーションモードだ。
全体のコードはこちらを参照してほしい。
1コンストラクター
Colorカメラやジェスチャーと同じように、EnableVoiceRecognition()(※本連載では関数は「()」で表現する)で音声認識を有効にする。
|
Pipeline(void)
: UtilPipeline()
{
// 必要なデータを有効にする
EnableVoiceRecognition();
}
|
2音声エンジンのセットアップを行う
OnVoiceRecognitionSetup()をオーバーライドし、使用する(日本語の)音声エンジンを設定する(次のコード)。
その関数内で、音声エンジンを扱うためのPXCVoiceRecognitionクラスをQueryVoiceRecognition()で取得する。
利用可能な音声エンジンは、PXCVoiceRecognition::QueryProfile()で取得する。
「PXCVoiceRecognition::ProfileInfo::language」に言語の種類が入っているので、「PXCVoiceRecognition::ProfileInfo::LANGUAGE_JP_JAPANESE」であるエンジンを、引数で渡されたfinfoに設定する。これで日本語を認識するようになった。
|
virtual void OnVoiceRecognitionSetup(PXCVoiceRecognition::ProfileInfo * finfo)
{
// 日本語の音声エンジンを探す
auto voiceRecognition = QueryVoiceRecognition();
for ( int i = 0; ; ++i ) {
PXCVoiceRecognition::ProfileInfo pinfo = { 0 };
auto ret = voiceRecognition->QueryProfile( i, &pinfo );
if ( ret != PXC_STATUS_NO_ERROR ) {
break;
}
if ( pinfo.language == PXCVoiceRecognition::ProfileInfo::LANGUAGE_JP_JAPANESE ) {
*finfo = pinfo;
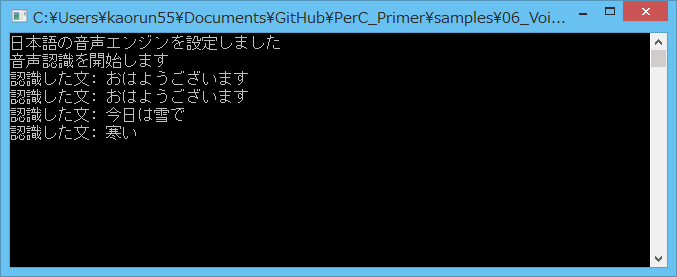
std::cout << "日本語の音声エンジンを設定しました" << std::endl;
}
}
std::cout << "音声認識を開始します" << std::endl;
}
|
3音声認識されたテキストを取得する
上記の処理を行うと、音声認識処理が開始される。マイクに向かってしゃべると、音声をテキスト化する。テキスト化された音声はオーバーライドしたOnRecognized()で受け取る(次のコード)。
認識したテキストについての情報が引数に返ってくる。この中の「PXCVoiceRecognition::Recognition::dictation」に、話した言葉を文字に起こした結果の文字列が入っている。
|
virtual void PXCAPI OnRecognized( PXCVoiceRecognition::Recognition *cmd ) {
std::wcout << L"認識した文: " << cmd->dictation << std::endl;
}
|
なお、「dictation」はpxcCHAR型の配列として定義されており、pxcCHAR型はwchar_tをtypedefしている。つまりワイドキャラクターになる。このワイドキャラクターに日本語の「ひらがな」や「漢字」は入ってくる。これをそのままstd::wcoutで出力しても、既定の設定ではコンソール画面には表示できない。そこで、プログラムの最初に「std::locale::global(std::locale("japanese"));」の1行を追加し、ワイドキャラクターのひらがなや漢字を表示できるようにしている(次のコード)。
|
int _tmain(int argc, _TCHAR* argv[])
{
try {
// 4.wide-charactorを表示できるようにする
std::locale::global(std::locale("japanese"));
Pipeline pipeline;
pipeline.LoopFrames();
}
catch ( std::exception& ex ) {
std::cout << ex.what() << std::endl;
}
return 0;
}
|
このプログラムを実行すると、話した言葉がテキスト化されて画面に表示される
音声合成
続いて音声合成だ。
音声合成はテキストをPerC SDKに渡し、音声データに変換してもらうだけなので、今までのように「UtilPipelineクラスを継承して」という必要はない。もちろんColorカメラやジェスチャー、音声認識と合わせてUtilPipelineクラスの派生クラスから利用することも可能だ。本プログラムを実行すると、入力したテキストの音声がスピーカーから出力されるので、スピーカー音量に注意してほしい。
全体のコードはこちらを参照してほしい。
1ヘッダーファイル
ここで使うヘッダーファイルは、util_pipeline.hとvoice_out.hの2つだ。util_pipeline.hファイルは、今までも使っていたUtilPipelineクラスのヘッダーで、今回は継承せずにそのまま利用する。voice_out.hファイルは、音声データをスピーカーに出力する機能を持ち、PerC SDKのサンプルコード内(「C:\Program Files (x86)\Intel\PCSDK\sample\voice_synthesis\include」以下)にあるものを利用している。voice_out.hファイルでは、winmm.libファイルをリンクする必要があるので、併せてリンクをしている。
|
#include "util_pipeline.h"
#include "voice_out.h"
#pragma comment( lib, "winmm.lib" )
|
2ワイドキャラクターを扱えるようにする
音声認識と同様にPerC SDK内でのテキストの扱いはワイドキャラクターである。コンソールアプリケーションでワイドキャラクターの日本語を扱うためにロケールを設定する。
|
std::locale::global(std::locale("japanese"));
|
3UtilPipelineクラスを利用する
今回はUtilPipelineクラスをそのまま利用する。UtilPipelineクラスのpipeline変数を定義し、UtilPipeline::Init()を呼び出すことで音声合成を含めて各機能を利用できる。
|
UtilPipeline pipeline;
pipeline.Init();
|
4音声合成の機能を利用可能にする
音声合成の利用方法は、前述の音声認識などの今までの方法とは異なる。今まではEnableXXX()で有効にしていたが、UtilPipeline::QuerySession()でセッションを扱うPXCSessionクラスを取得し、PXCSession::CreateImpl()で音声合成のためのPXCVoiceSynthesisクラスのインスタンスを取得する。
|
PXCVoiceSynthesis* synthesis = nullptr;
pipeline.QuerySession()->CreateImpl<PXCVoiceSynthesis>( &synthesis );
|
5音声エンジンを設定する
音声認識と同じように日本語の音声エンジンを設定する。利用可能な音声エンジンはPXCVoiceSynthesis::QueryProfile()で取得する。返されたPXCVoiceSynthesis::ProfileInfo構造体のlanguageに国の識別子が入っているので、「PXCVoiceRecognition::ProfileInfo::LANGUAGE_JP_JAPANESE」である音声エンジンを設定する。音声エンジンの設定はPXCVoiceSynthesis::SetProfile()だ。
|
PXCVoiceSynthesis::ProfileInfo pinfo = { 0 };
for ( int i = 0; ; ++i ) {
auto ret = synthesis->QueryProfile( i, &pinfo );
if ( ret != PXC_STATUS_NO_ERROR ) {
break;
}
if ( pinfo.language == PXCVoiceRecognition::ProfileInfo::LANGUAGE_JP_JAPANESE ) {
synthesis->SetProfile( &pinfo );
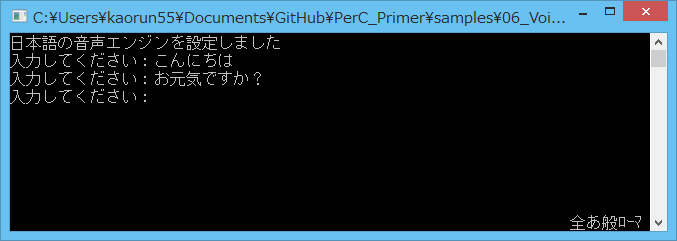
std::cout << "日本語の音声エンジンを設定しました" << std::endl;
break;
}
}
|
6テキストを音声化し、スピーカーから出力する
実際の音声合成処理は以下のコードのみだ。音声化したいテキスト(ワイドキャラクター)をPXCVoiceRecognition::QueueSentence()に入れ、処理を開始する。音声合成処理はPXCVoiceRecognition::ProcessAudioAsync()で行い、PXCVoiceRecognition::Synchronize()で終了を待つ。音声合成されたデータは、PXCAudioクラスが持っているので、それをVoiceOut::RenderAudio()でスピーカーに出力する。ちなみに音声データ自体を取得するには、「PXCAudioクラスを使って、Colorカメラなどと同じようにAcquireAccess()でデータ取得、データポインターを処理」という流れになる。コードはVoiceOut::RenderAudio()内を参照してほしい。
|
VoiceOut voice( &pinfo );
while ( 1 ) {
std::cout << "入力してください:";
std::wstring message;
std::wcin >> message;
// 音声合成のキューに入れる
pxcUID id=0;
synthesis->QueueSentence( (wchar_t*)message.c_str(), message.size(), &id );
for (;;) {
PXCSmartSP sp;
PXCAudio *sample;
// 音声合成を行う
auto ret = synthesis->ProcessAudioAsync(id, &sample, &sp);
if ( ret<PXC_STATUS_NO_ERROR ) {
break;
}
ret = sp->Synchronize();
if ( ret<PXC_STATUS_NO_ERROR ) {
break;
}
// 音声データをスピーカーに出力する
voice.RenderAudio(sample);
}
}
|
このプログラムを実行すると、入力した文字を音声化したものがスピーカーから出力される。
まとめ
以上でPerC SDKを使ったColorカメラ、Depthカメラ、音声機能の解説は終了だ。ここではC++での解説だが、.NETやUnity、openFrameworks環境でも同じように利用できる。OSはWindowsに限られるが多くの環境で利用できるため、選択肢の1つに加えていただければ幸いだ。
蛇足になるがSenze3Dは「Oculus Rift」と呼ばれるHMD(Head Mounted Display)の「目」としても利用できる。少し前にOculus RiftにSenze3DをマウントできるCADデータが公開されていた。これを3Dプリンターでプリントし、Oculus Riftに載せることでSenze3DのColorカメラ画像や指の動きをOculus Riftのアプリケーションに合わせることができる。Oculus Rift、Senze3D(PerC SDK)ともにUnityに対応しているため、組み合わせも簡単にできる。要望があればこちらも記事として書ければと思っている。

1. Intel Perceptual Computing(PerC) SDKの全体像
Intel Perceptual Computing SDKの概要と、それを利用したアプリの開発方法について解説する連載スタート。今回はセンサーモジュールの仕様や、SDKの概要、Intel社の3Dセンシング技術などについて紹介。
2. Intel Perceptual Computing(PerC) SDKの概要と環境構築
PerC SDKの開発環境やアーキテクチャ、インストール方法について解説。またSDKに含まれているサンプルを紹介することで、PerCが提供する機能について見ていく。
5. 【現在、表示中】≫ 無償で簡単にアプリに組み込める「音声認識&音声合成」
マイクに向かってしゃべると音声をテキスト化する「音声認識」や、テキストを音声データに変換する「音声合成」をPC上のアプリで実現したい場合、無償のPerC SDKが便利だ。その開発方法を解説。