
Build Insiderオピニオン:岩永信之(11)
nullが生まれた背景と現在のnullの問題点 ― null参照問題(前編)
Cの系譜を継ぐC#ではnullが長らく使い続けられてきたが、最近ではその存在が大きな問題だと認識されている。前後編でこの問題を取り上げ、今回(前編)はnullを取り巻く事情について考察する。
近年、nullの存在は、billion dollar mistake(10億ドル規模の損失をもたらす過ち)と呼ばれるくらい忌避されるものになっている。
nullは、低コストでそこそこ安全に参照を扱えるという意味で悪くない妥協ではあるが、技術が進歩した現在ではもう少し賢い参照の扱い方があるはずである。C#のように、これまでnullを認めてしまっているプログラミング言語で、今からそれを完全になくすというのは現実的ではないが、nullに起因する問題を少しでも避ける手段はこれからでも追加していけるだろう。
今回は、nullが生まれるに至った背景から始め、nullが抱える問題や、nullを避けるに当たっての課題などについて説明していく。そして、nullに対するC#の現在の取り組み状況について触れる。
初期化処理とnull
null自体の話の前段階として、変数やフィールドの初期化についての話から始めたい。
不定動作
メモリというのは確保した時点ではどういう状態になっているか分からず、誰かが適切に初期化しなければ不定な動作を招く。C#ではあまり気にすることはないが、それは.NETランタイムやC#コンパイラーが適切に初期化作業をしてくれているからである。
説明のために、あえて不定動作を起こしてみよう。C#でも、unsafeコンテキストでは不定動作を起こすことができる。例えばリスト1のようなコードを書いたとしよう。AllocHGlobalメソッドでメモリ確保したての領域に入っている値を出力している。
|
using System;
using System.Runtime.InteropServices;
class Program
{
unsafe static void Main()
{
var pb = (byte*)Marshal.AllocHGlobal(4);
for (int i = 0; i < 4; i++)
{
Console.WriteLine(pb[i].ToString("X2"));
}
Marshal.FreeHGlobal((IntPtr)pb);
}
}
|
このコードは実行するたびに異なる値が表示される。確保したてのメモリ領域には決まった値が入っていないのである。この領域が以前使われたときに入っていた値がそのまま残っているが、いつ誰がどう使ったものなのかを知るすべはなく、実質的には不定な値といってよい。この状態を「未初期化」と呼ぶ。
安全性の観点からいうと、未初期化領域を残すことはトラブルの原因となる。不定動作なため、たまたまテストをすり抜けてしまったバグが、本番環境で顕在化するといったこともあり得る。
確実な初期化
話を通常の(safeな)コンテキストに戻そう。通常、C#ではこのような不定動作は起きない。以下の2つのルールがあり、変数やフィールドは必ず初期化されるようになっている。
- 確実な代入: 値を代入しないままローカル変数を読み出すとコンパイルエラーになる
- 既定値による初期化: フィールドや配列の要素は0初期化する
まず、ローカル変数では、何も代入していない状態の変数から値を読み出すことができない。図1に例を示すように、コンパイラーがフロー解析(=ソースコードの制御フローを追って変数の利用状況を調べる)をして、値を代入していない変数の読み出しがあればコンパイルエラーにする。これを「確実な代入ルール」(definite assignment rule)という。
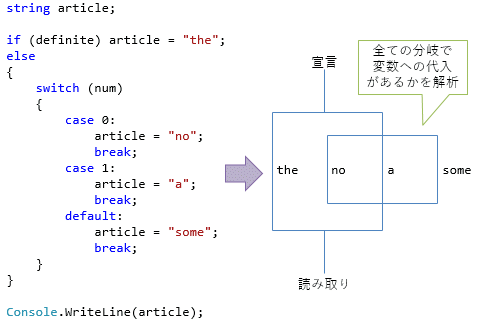
フィールドや配列の要素に対しては、new演算子でインスタンスを作った時点で全て既定値(default value)に初期化される。既定値というのは要するに0初期化のことで、0、false、'\0'、nullなど、(C#では)内部表現的には全てのビットが0の値で初期化される。
ようやく本稿の主題であるnullが出てきたわけである。要するに、nullというのは、不定動作と比べれば0初期化の方がマシという妥協の産物といえる。少なくとも「無効な参照」ということが確実に分かって、決定的に「null参照エラー」を起こせるという点では有益である。パフォーマンス的にも、0初期化であれば耐えられないほどの負担にはならない。悪くない妥協だろう。
有効な値の確実な代入
ここで1つの疑問が生じる。フロー解析で確実な代入を調べられるのなら、「有効な値を代入した」というのもフロー解析で調べられるはずである。なのにどうして、既定値(=0初期化。0が無効な値なこともあり得る)による初期化を必要とするのだろうか。
理由は単純で、有効な値で初期化できない場面がどうしても残るからである。有名なものは以下の2つだろう。
- 大き目のバッファー領域を確保する場合
- 循環参照がある場合
大き目のバッファー確保は、要するにList<T>クラス(System.Collections.Generic名前空間)などが内部で行っていることである。最低限の説明のために必要な部分を抜き出すと、リスト2のような状態である。
|
using System;
class List<T>
{
T[] _buffer;
int _count;
public List(int capacity)
{
// 事前に大き目の領域を確保しておくが、中身は使わない
_buffer = new T[capacity];
_count = 0;
}
public void Add(T item)
{
// _count番目の要素に有効な値を代入
_buffer[_count] = item;
_count++;
}
}
|
今現在使う分だけの配列を作るのでは、Addするたびに配列の確保し直しが発生して、パフォーマンス的にかなり厳しい。そこで、この例のように事前に大き目の配列を作ってしまって、満杯になるまでは同じ配列に値を追加して(配列のサイズを超えたら、そこで新たに配列を確保し直して)いくという手法がとられる。
もう一つの循環参照は、リスト3のような状況である。
|
class Node
{
public Node Ref;
public static (Node a, Node b) Create()
{
var a = new Node();
var b = new Node { Ref = a };
a.Ref = b;
return (a, b);
}
}
|
2つのインスタンスが互いを参照している。2つ目に作ったbの方は、newの時点でRefプロパティに有効な値を渡すことができるが、1つ目のaの方は原理的に不可能である。bが作られるまで、a.Refを有効な値で埋めることはできない。
2例ほど紹介したが、これらの状況下でも不定動作は起こさないようにするためにあるのが、既定値(null)による初期化である。
nullの許容/拒否の区別
後述するが、nullを完全になくそうとすると過剰なコストが発生する場面もある。また、C#のように現在nullを持ってしまっている言語からnullを取り除くというのは現実的ではない。とはいえ、nullは多くの場面で必要なく、むしろ「nullが来ることを期待していないのにnullが来る」というバグの原因になっている。少なくとも、nullの許容/拒否(nullability)を区別できる必要があるだろう。
nullの許容/拒否は型で表現すべき
C#は「静的な型付けの言語」や「コンパイル型の言語」などといわれている。こういうタイプのプログラミング言語は、リスト4に示すように、以下のような利点を持っている。
- メソッドのシグネチャ(=メソッド名と引数リスト)だけ見れば、そのメソッドがどういうデータを受け付けるのか一目で分かる
- ビルド時に、コンパイラーが判断できるエラーは全て取ってしまえる
|
class Program
{
// シグネチャ(「F(int x)」という部分)だけ見て、
// このメソッドがどういうデータを受け付けるかが分かる
static int F(int x) => x * x;
static void Main()
{
// intを求めるメソッドにstringを渡していて、正しく動かないことは明白
// コンパイル時に間違いが分かるので、修正を強制できる
var x = F("abc");
}
}
|
ところが、nullの許容/拒否の判定に関しては、上で述べた「静的な型付け」「コンパイル型」の利点から漏れてしまっている。リスト5に示すように、nullの許容/拒否はメソッドシグネチャに表れず、実行してみないとエラーかどうか分からない状態である。
|
class Program
{
// こちらはnull拒否。nullが来ると実行時エラー
static int F1(string x) => x.Length;
// こちらはnull許容。nullが来ても平気
static int F2(string x) => x?.Length ?? -1;
// でも、シグネチャはF1(string x)とF2(string x)で、
// nullの許容/拒否が分からない
static void Main()
{
// F1は実行時エラーで、F2は平気
// でも、実行してみるまで間違いには気付けない
var x = F1(null);
var y = F2(null);
}
}
|
これは、静的な型付けの言語としては好ましくない状況である。本来であれば、int型とstring型を区別できるのと同程度に、nullを許可するか拒否するかも型を見て区別できるべきだろう。
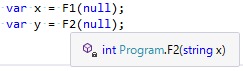
ちなみに、シグネチャだけ見て分かるというのは結構重要なポイントとなる。コンパイル済みのライブラリだけで(=ソースコードなし)で知ることができる情報はこのシグネチャの部分だけである。情報がないものを表示することはできないわけで、例えばVisual Studio上で、メソッドF1、F2を参照すると図2のようなヒントが表示されるが、ここにはメソッドのシグネチャしか表示されない。
そして、シグネチャを見て分からない/実行するまで分からないことによって、「過剰防衛」が発生することも多い。例えばリスト6のように、呼ぶ側と呼ばれる側の両方で同じnullチェックを繰り返すことがある。これは完全に無駄な処理で、nullの許容/拒否が分かりにくいことによって発生するコストである。
|
static void Caller(string s)
{
if (s == null) throw new ArgumentNullException(nameof(s));
Callee(s);
}
static void Callee(string s)
{
if (s == null) throw new ArgumentNullException(nameof(s));
Console.WriteLine(s.Length);
}
|
これまでのnull許容型
C#には、C# 2.0からnull許容型(nullable type)という機能が存在する。int型など、値型と呼ばれる本来はnullがあり得ない型に対してnullの代入を認める機能である。リスト7に示すように、型名の後ろに?(疑問符)を付けることで、「null+本来の値」を代入できる型を作れる。
|
// 値型はnullにはできない
int i1 = 1; // OK
int i2 = null; // コンパイルエラー
// 値型にnullを追加したのがnull許容型
int? n1 = 1; // OK
int? n2 = null; // OK
|
これによって、値型の場合にはnullの許容/拒否の区別を型で表現できている。ただ問題は、値型の場合だけでしか表現できていないという点だ。参照型の場合は常にnullを認めてしまっていて、拒否する手段が用意されていない。つまり、図3の上段に示すような非対称が発生している。
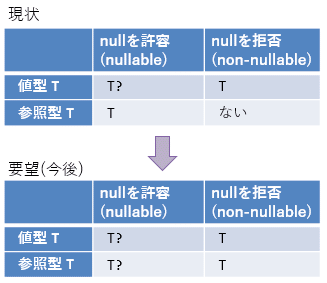
当然、参照型にもnullの許容/拒否の区別を導入してほしいという話はC# 2.0以来ずっといわれ続けている。値型との一貫性を考えると、図3の下段のように、「T」でnullを拒否(non-nullable)、「T?」で許可(nullable)とすべきだろう。しかし、挙動を変更するためには、既存ソースコードを壊さないよう、旧仕様(Tのみ)と新仕様(TとT?を区別)の切り替えオプションが必要になる。どういう形でオプション指定できるようにするかや、新旧世界に分かれてしまうことの是非などが問われている。
まとめ
null(要するに0初期化による「不定動作」除け)は、低コストで比較的安全な動作を得られるため、妥協的に重宝されている。その一方で、意図してnullを必要とする場面はそう多くない。また、意図的にnullを使っているのか、何らかのミスでnullが残っているだけなのかが分からなくて困るといった問題が出ている。
C#でもこの問題を解消してほしいという要望はかねてから出ているが、既存ソースコードを壊しかねない問題であるため、慎重な姿勢を示している。しかし、いつまでも避けて通れるものではない。
岩永 信之(いわなが のぶゆき)

※以下では、本稿の前後を合わせて5回分(第9回~第13回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
9. C# 7、そしてその先へ: 非同期処理(前編) - Task-like
C#の進化の中でも「非同期メソッド」はコーディング方法を大きく変えるほど革新的だったが、そこにはまだ課題もある。C# 7~将来のC#で、非同期処理はどう進化するのか、前後編で見ていこう。
10. C# 7、そしてその先へ: 非同期処理(後編)- 非同期シーケンス
C#(とVisual Basic)が切り開いた非同期処理の新たな世界。そこにはまだ課題もある。これを克服する方法として、前後編の後編となる今回は「非同期シーケンス」がC# 7でどうなるかを見てみよう。
11. 【現在、表示中】≫ nullが生まれた背景と現在のnullの問題点 ― null参照問題(前編)
Cの系譜を継ぐC#ではnullが長らく使い続けられてきたが、最近ではその存在が大きな問題だと認識されている。前後編でこの問題を取り上げ、今回(前編)はnullを取り巻く事情について考察する。
12. C#でのnull参照問題への取り組み ― null参照問題(後編)
最近のC#ではnullの存在が大きな問題となっている。前回(前編)で説明したnullの事情を踏まえ、今回(後編)は、将来のC#がnullをどう取り扱っていくのかを見ていく。
13. インターフェースを「契約」として見たときの問題点 ― C#への「インターフェースのデフォルト実装」の導入(前編)
C#におけるインターフェースとは、ある型が持つべきメソッドを示す「契約」であり、実装は持てない。だが、このことが大きな問題となりつつある。今回から全3回に分けて、C#がこの問題にどう対処しようとしているかを見ていく。