
Build Insiderオピニオン:岩永信之(12)
C#でのnull参照問題への取り組み ― null参照問題(後編)
最近のC#ではnullの存在が大きな問題となっている。前回(前編)で説明したnullの事情を踏まえ、今回(後編)は、将来のC#がnullをどう取り扱っていくのかを見ていく。
前編では、nullが存在する理由や、nullがあることで起こっている問題などについて説明してきた。
後編では、C#が具体的にどう課題に取り組んでいくかについて見ていこう。C# 7よりも先の話でまだ仕様は固まっていないが、現状での仮実装や、検討として挙がっている項目について説明していく。
無効な値の表現
ただし、「具体的にどう取り組んでいくか」の話の前に、「型を使ったnullの許容/拒否の区別」とは別軸で「無効な値を表現するのにnull(0初期化)が適切かどうか」という問題もある。まずはこちらについて話しておこう。
型情報の紛失
nullは、どんな型だろうが一律に0埋めすることで、最低限、無効であることが分かるようにしたものだ。それ以外の情報は完全に抜け落ちる。特に困るのは型情報の紛失だろう。リスト8に例を示そう。
|
using System;
class Program
{
static void Main()
{
TypeInfo((string)null);
TypeInfo((int?)null);
string s = null;
// これですらfalse。nullから型は判別できない
if (s is string) Console.WriteLine("string");
// 「int?型のnull」を代入しているように見えて、int?の型情報は残らない
// 「ただのnull(型はない)」という扱い
object obj = (int?)null;
// 結果、string型に代入できる。エラーにならない
s = (string)obj;
}
static void TypeInfo<T>(T obj)
{
// objがnullのとき、
// 例えTがstringでもこの条件はfalse
if (obj is string) Console.WriteLine("string");
// 例えTがint?でもこの条件はfalse
if (obj is int?) Console.WriteLine("int?");
try
{
// 当然null参照例外を起こす
Console.WriteLine(obj.GetType());
}
catch(NullReferenceException)
{
// この行しか表示されない
Console.WriteLine("error");
}
}
}
|
このコードを実行すると、「error」の文字以外は表示されない。nullに対するis演算子は全てfalseを返し、GetTypeメソッド呼び出しはnull参照例外を起こす。
型情報を紛失して困るのは、だいたい動的な処理を行いたい場合である。代表例は、オブジェクトのシリアライズだ。「シリアライズ結果から型を復元できない」ということがあり得る。
◎補足: null許容型のobject型への代入
null許容型の挙動に関して1点補足しておこう。リスト8の例では、int?型をobject型に代入しているが、このとき、少し特殊な処理が行われている。C# 2.0で導入されたnull許容型は、実際にはリスト9のような構造体である(int?と書くと、Nullable<int>が作られる)。
|
public struct Nullable<T> where T : struct
{
public bool HasValue { get; }
public T Value { get; }
public T GetValueOrDefault();
}
|
通常、構造体の値をobject型の変数に代入すると、box化(=ヒープを確保して、スタックからヒープへ値をコピー)が発生する。ところが、Nullable<T>構造体に関しては、JITコンパイルの際に、リスト10に相当する特殊処理が掛かる。box化というそれなりに負担がある処理を避けられる代わりに、型情報を紛失している。
|
static void Box(int? x)
{
object obj = x.HasValue ? (object)x.GetValueOrDefault() : null;
}
|
無効な値を表す型
型情報の紛失を嫌って、null自体をなくそうという考え方も存在する。無効な値を表すのに、nullの代わりにリスト11に示すような型を作って使おうというものである。多くの場合、Optional<T>型(なくてもいいT型)やMaybe<T>型(恐らくTが入っている型)と名付けられる。
|
public struct Optional<T>
{
public bool HasValue { get; }
private T _value;
public Optional(T value)
{
HasValue = true;
_value = value;
}
public T Value => HasValue ? _value : throw new NullReferenceException();
public T GetValueOrDefault() => _value;
}
|
これは、実装としてはリスト9に示したNullable<T>型とほぼ同じで、以下のような型である。
- 値と、値を持っているかどうかを表す
bool型のメンバーを持っている(=bool型1個分余計にメモリを使う)
一方、以下の点で異なっている。
- 型引数
Tにstruct制約がない(=クラスに対しても使える) - box化の際の特殊処理をしない(=型情報を紛失しない代わりに、ヒープ確保が発生)
結局は、型情報を取るか、パフォーマンスを取るかのトレードオフである。利便性と引き換えに、bool型1個分のメモリと、box化のコストを負う。あとは、コストをどこまで許容するかという問題だろう。
bool型1個だけなら高々1Byteの小さなコストと思うかもしれないが、これは正しくない。実際には、アライメント(=CPUのメモリアクセスが効率的に行えるように個々のフィールドのメモリ配置を調整する処理)の必要性があって、T?型はT型の2倍のメモリを必要とする。図4に例を示すように、値の配置をきれいに調整するために隙間が作られる。
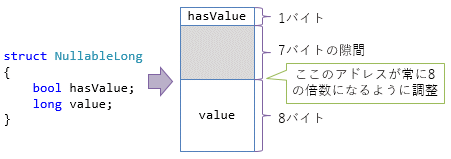
int?型であれば8Byte(元のint型は4Byte)になるし、long?型であれば16Byte(64bit CPUの場合。64bit CPUではlong型は8Byte)になる。参照型の場合は、32bit CPUであれば8Byte、64bit CPUであれば16Byte必要だ(いずれも元の型の2倍)。意外とコストは大きい。
box化(=object型やインターフェース型の変数への代入時に発生)のコストはさらに大きい。図5に示すように、数十バイトのメモリ確保が発生する。
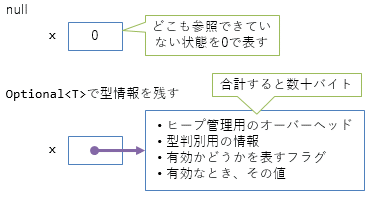
パフォーマンスへの配慮
このように、「無効な値の表し方」をどうするかは、利便性とパフォーマンスのトレードオフである。どちらを取るかは主義の問題だろう。C#では、パフォーマンスの側を取ることになりそうだ。
もちろん時代とともにコンピューターの性能はどんどん上がっていて、富豪的なやり方が許容されやすくなっているし、安全性が最優先になってきている。それでも、パフォーマンスは疎かにはできない。
「パフォーマンスを犠牲にしてでも利便性第一主義」と「パフォーマンスも出なければやはり使えない主義」は、周期的に現れるものである。この手のトレンドは往々にしてループしている(自動車のデザインのはやりに角張ったものと丸みのあるものが交互に現れるようなものである)。パフォーマンスをあまりに疎かにすると、パフォーマンスの波が回ってきた時に後悔することになる。
パフォーマンスへの配慮もあって、C#では、「無効な値」を以下のように扱う。
- 無効な値の表現にはこれまで通り
nullを使う(=型情報は紛失する) nullの許容/拒否だけを、「T」(拒否)と「T?」(許可)で区別できるようにする
要するに、参照型に対するnull許容型(T?型)の導入である。
null許容参照型
前置きが長くなったが、結局のところ、C#で考えられている「null対策」は、参照型でもnullの許容/拒否を型として表現できるようにすることである。現在、値型にだけ認められているnull許容型を、参照型にも導入したいというものだ。大まかにいうと以下のような要素からなる。
- 型表記の追加:
null許容(nullable)な参照型として、「T?」という表記を追加する。今後は、単なる「T」型の変数に対してはnullの代入を認めない(non-nullable) - フロー解析:
null許容な変数からnullチェックなしで値を読み出そうとした場合や、非null許容型(nullを拒否する型)な変数にnullを代入しようとしたときに警告を出す
要するに、リスト12のような構文の導入を検討している。
|
// nullを受け付けない(null拒否)
static int M(string x) => x.Length;
// nullを受け付ける(null許可)
static int N(string? x) => x?.Length ?? -1; // nullが来ることを想定したコード
static void Main()
{
M("ab"); // OK
M(null); // これまではOKだったが、今後、警告を出す
N("ab"); // OK
N(null); // OK
}
|
ちなみに、内部実装としては、null許容型(T?型)に対してNullable属性が付く。リスト12のメソッドM、Nであれば、リスト13のように展開される。
|
// 非null許容の方はそのまま
static int M(string x) => x.Length;
// null許容の方にNullable属性が付く
static int N([Nullable(new[] { true }]] string x) => x?.Length ?? -1;
|
Nullable属性の引数がbool型の配列になっているのは、ジェネリックな型や、配列に対してどの型引数/どの次元がnull許容なのかを指定するためである。例えば以下のような区別ができる。
string?[]… 要素はnull許容、配列自体はnull拒否string[]?… 要素はnull拒否、配列自体はnull許容string?[]?… 要素も配列自体もnull許容Dictionary<string?, string>… 1つ目の型引数だけがnull許容、2つ目の型引数とDictionary自体はnull拒否
選択式の警告
リスト12に示す構文では、これまで何の警告も出なかったソースコードに対して、新たに警告が追加されている。警告といえども、追加は破壊的変更である。C#コンパイラーには「警告をエラーとして扱う」というコンパイルオプションがあり、一定数のプロジェクトでこのオプションが使われている。すなわち、警告の追加は既存プロジェクトのビルドを壊す可能性がある。
そこで今考えられているのは、「警告ウェーブ」(warning waves)という手法である。C# 8の警告、C# 9の警告……というように、警告にバージョンを持たせて、それを選択して使えるようにする計画だ。既存のプロジェクトに対しては、明示的に選択するまでバージョンを上げないようにすればビルドを壊さない。
また、場合によっては、「警告ウェーブを上げたいけれども、null許容参照型がらみの影響が大きすぎるので対応しきれない。null検査警告だけは抑止したい」という状況もあり得るだろう。そういうときのために、抑止用の属性も提供する予定である。今あるプロトタイプ実装では、NullableOptOutForAssembly属性(moduleに対して付けることでプロジェクト全体に有効)やNullableOptOut属性(型やメソッドなど、個別に警告をオン/オフする)という名前になっている。
属性ベース(T?型の実体はT型のまま)
Nullable属性を付けてnull許容参照型を表す方法は、実行時に余計なコストを生まないという利点がある一方で、いくつか問題もある。
属性の有無しか差がないということは、参照型のT?型は、内部的にはT型のままである。すなわち、T?型とT型の引数違いでメソッドをオーバーロードすることができない。リスト14に示すように、値型と参照型で挙動が違うということになる。
|
// 値型の場合は実際に型が異なり、オーバーロード可能
void M(int x) { }
void M(int? x) { } // OK
// 参照型の場合はコンパイル結果的には同じ型になり、オーバーロード不可
void M(string x) { }
void M(string? x) { } // コンパイルエラー
|
また、属性を付けられない場所が存在する。代表的な例は、リスト15に示すような、インターフェースの型引数である。
|
class Sample : IEnumerable<string> // ここのstringには属性を付ける手段がない
{
public IEnumerator<string> GetEnumerator() => new string[] { null };
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator()
}
|
一定期間はnullが発生
nullを使いたくない場合でも、一時的にどうしてもnullを避けられない場面が存在する。そもそも、配列を確保した直後や、既定値の必要性の説明(前回)で例に出した循環参照がその代表例だ。
T型(null拒否)の配列を作りたい場合、new T[N]した時点では全ての要素がnull初期化されている。この挙動は今後も変わらず、一時的にnullが発生する。この一時的なnullに対しては、リスト16に示すように、特定の範囲(コンストラクターなど)を抜けるまでに全ての要素を有効な値で初期化することを義務付けることで対処する。
|
class Sample
{
private string[] nonNullStrings;
public Sample()
{
// この時点では配列の各要素はnull
nonNullStrings = new string[3];
// 有効な値で初期化する前に要素を読み出すと警告
//var len = nonNullStrings[0].Length;
nonNullStrings[0] = "one";
nonNullStrings[1] = "two";
nonNullStrings[2] = "three";
// コンストラクターを抜けるまでに全ての要素を有効な値で初期化しないと警告
}
}
|
問題が深刻なのは循環参照だ。前編のリスト3で示したように、コンストラクター内ではnullを解消できない。この問題を真面目に解消しようと思うと過剰なコスト(構文の複雑化や、実行時の負担)になりかねない。循環参照はそれほど高頻度で起こるものではなく、妥協することになるだろう。例えば、リスト17に示すように、前述のNullableOptOut属性を付けることでnull検査警告をオフにして、コードを書く人の裁量に任せるべきかもしれない。
|
class Node
{
// ?が付いていないのでnull拒否
public Node Ref;
[NullableOptOut]
public static (Node a, Node b) Create()
{
// このメソッド内ではnull検査をしない
// 有効な値が代入されているかどうかの保証はコードを書く人の裁量に任せる
var a = new Node();
var b = new Node { Ref = a };
a.Ref = b;
return (a, b);
}
}
|
default(T)問題
既定値による初期化の問題は、何も参照型だけのものではない。分かりやすいのは、リスト18に示すような、参照型を含んだ構造体におけるnull検査だろう。nullを避けたければ、値型の既定値(=0クリアなので、メンバーがnullになる)も避ける必要がある。
|
// 用途を明示するために作ったstringの薄いラッパー
struct Name
{
// ?を付けていないのでnull拒否のつもり
public string Value { get; }
public Name(string value) { Value = value; }
}
class Program
{
static void Main()
{
var valid = new Name("John"); // OK
var invalid = new Name(null); // null検査に引っかかって警告が出るはず
var unknown = default(Name); // nullが入ってしまう
}
}
|
今回の主題であるnull検査以外にも、リスト19に示すような、制限付きの値を持つ構造体では、既定値による0クリアが不正な値になることがある。
|
using System;
struct PositiveInt
{
// 正の数に制限したい
public int Value { get; }
public PositiveInt(int value)
{
// コンストラクターで0以下をはじいているものの、
// default(PositiveInt)で値を作るとValueが0になる
if (value <= 0) throw new ArgumentOutOfRangeException();
Value = value;
}
}
|
おそらくは、null検査のフロー解析をするのであれば、セットで「default検査」もすべきだろう。nullの許容/拒否だけでなく、値型のdefaultの許容/拒否も選択できるべきである。
まとめ
後編では、nullに関連する問題に対して、C#が今後どう取り組むかについて紹介した。
もともとnullを持っている言語からnullをなくすのは現実的ではないが、少なくとも、型でnullの許容/拒否を表現できるようにして、意図しないnullはコンパイル時に警告を出してはじくようにすべきである。
古いバージョンとの互換性やパフォーマンスへの配慮もあって、なかなか完璧とはいえない妥協的な実装にはなりそうだ。しかし、互換性とパフォーマンスは、疎かにしてはいけない非常に重要な要素である。ここを疎かにすると、確実に言語の寿命を縮めることになる。
それでも、警告ウェーブの導入など、既存資産を壊さないようにしつつ、これまでにあった問題を解消するための仕組みも検討されている。
岩永 信之(いわなが のぶゆき)

※以下では、本稿の前後を合わせて5回分(第10回~第14回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
10. C# 7、そしてその先へ: 非同期処理(後編)- 非同期シーケンス
C#(とVisual Basic)が切り開いた非同期処理の新たな世界。そこにはまだ課題もある。これを克服する方法として、前後編の後編となる今回は「非同期シーケンス」がC# 7でどうなるかを見てみよう。
11. nullが生まれた背景と現在のnullの問題点 ― null参照問題(前編)
Cの系譜を継ぐC#ではnullが長らく使い続けられてきたが、最近ではその存在が大きな問題だと認識されている。前後編でこの問題を取り上げ、今回(前編)はnullを取り巻く事情について考察する。
12. 【現在、表示中】≫ C#でのnull参照問題への取り組み ― null参照問題(後編)
最近のC#ではnullの存在が大きな問題となっている。前回(前編)で説明したnullの事情を踏まえ、今回(後編)は、将来のC#がnullをどう取り扱っていくのかを見ていく。
13. インターフェースを「契約」として見たときの問題点 ― C#への「インターフェースのデフォルト実装」の導入(前編)
C#におけるインターフェースとは、ある型が持つべきメソッドを示す「契約」であり、実装は持てない。だが、このことが大きな問題となりつつある。今回から全3回に分けて、C#がこの問題にどう対処しようとしているかを見ていく。
14. デフォルト実装の導入がもたらす影響 ― C#への「インターフェースのデフォルト実装」の導入(中編)
前回は一般論としてのインターフェースとその課題を見た。今回はC#にインターフェースのデフォルト実装を導入すると、どのようなコードが書けるようになるのか、導入するために必要な修正点などについて見ていく。