書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(5)
機械学習ハードウェアの基礎知識: 特定用途向け集積回路「ASIC」
特定アプリケーションに特化した回路を集積する方法であるASICについて概説。アプリケーションを表現するアルゴリズムのソフトウェア実装とASIC実装を比較しながらASIC実装の特徴と制約を説明する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「第2章 従来のアーキテクチャ、2.1 ハードウェア実装の現実」を転載しました。今回は、「2.2 特定用途向け集積回路(ASIC)」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
2.2 特定用途向け集積回路(ASIC)
ここではアルゴリズムのソフトウェア・プログラム実装とASIC実装を比較しながらASIC実装の制約を含めて説明する。
利用者の抱える問題・課題を解決する目的であるアプリケーションは、一般にアルゴリズムで表現される。アルゴリズムは何らかの値を保持する変数、一つ以上の変数を引数として演算を行う演算そのものを指定する演算子、演算結果を変数へ代入するための代入操作の3つの要素で構成される。ハードウェア実装ではさらに変数のメモリと演算回路の間での転送も要素として存在する。
今日、アルゴリズムの表現方法であるソフトウェア・プログラム(一般に単にプログラムと呼んでいる)は、これらの要素を使用してプログラムを記述し、上の行から下の行へ順に時系列で実行されることを前提としている。プログラムはプロセッサとメモリを使用して命令メモリにあるプログラムを上から下へ順に命令列から命令を読み取り、その命令を解釈(Decode、復号という)し、演算回路で逐次実行する。一般に制御フローの変更を決める変数は制御レジスタの一部としてプロセッサ上に実装され、ソフトウェア・プログラムから隠蔽されており、直接代入操作はできない。代わりに、プログラミング言語は制御フローを表現する文法を持ち、比較命令などでその制御レジスタを更新して分岐命令の実行時にその制御レジスタを参照して命令実行の流れを変更(分岐)させている。ハードウェアの場合はアプリケーションをハードウェア記述言語(HDL; Hardware Description Language)で記述するのが一般である。論理回路では回路上を流れる信号に対して逐次実行性は無いので、全ての代入操作は同時に発生する。ただし、一つの変数に対して複数の代入操作が起こり得ないように代入の優先順位を考慮して記述している。
2.2.1 アプリケーションの特性:局所性と依存性
ここではアプリケーション(アルゴリズム)をソフトウェアとハードウェアとして実装する際に現れる特性である局所性(Localities)と依存性(Dependencies)を取り上げる。実装の際にアプリケーションの持つこれらの特性をより良く利用・応用しているプラットフォームが性能やエネルギー効率が良く、この2つの要素は重要な着目点である。
例えばソフトウェアの場合、そのプログラムは連続したメモリ空間にストアされ、特定の実行パターンを持つのが一般である。プログラムを構成する命令列とデータそれぞれに、プログラムの任意の変数について各ステートメント間の実行順序と関係する特性である依存性(Dependency)と実行中のメモリアドレスのパターンとして現れる局所性(Locality)と言う2つの特性が存在する。
- 局所性(Localities)
命令列を構成する各命令はプログラムがストアされている命令メモリのメモリアドレスで区別可能(図2.4(a)参照)であり、データについても一般にデータメモリのメモリアドレス上に特定データ(あるいは変数)がストアされるので、命令同様にメモリアドレスで個々のデータを区別可能である。
制御フローの分岐について同じ分岐先命令のメモリアドレスを更新する、特定命令列部分(Basic Block、基本ブロックと呼ぶ)の繰り返し実行時に典型的な命令実行パターンが存在する(例えば図2.4(b)中“BB-F”のループ実行が該当)。 図2.4(a) Program in Memory and Control Flow at Execution.: Program(Basic Blocks)in Memory.
図2.4(a) Program in Memory and Control Flow at Execution.: Program(Basic Blocks)in Memory.
プログラムは上から順に実行する逐次実行の前提から、命令メモリアドレスはインクリメント(例えば+1)を続けて、Basic Blockの最後の手前付近に位置する分岐を決める計算を行う命令とその後のBasic Block終端にある分岐命令により制御フローが変更され命令メモリアドレスが大きく変化する(アドレスの変化の大きさが例えば1より大きい)。 図2.4(b) Program in Memory and Control Flow at Execution.: Control Flow for Basic Blocks.
図2.4(b) Program in Memory and Control Flow at Execution.: Control Flow for Basic Blocks.
命令列についてその逐次実行性から大抵の場合次に実行する命令が次の命令メモリアドレス上に存在する。命令メモリアドレス空間上でインクリメントした命令アドレスへアクセスするこの局所的なアドレス値のパターンの特性を空間的局所性(Spatial Locality)と言う。
制御フローについて特定のBasic Blockを繰り返し実行する時、この繰り返し実行するBasic Blockはアクセスしている命令メモリアドレスに着目すると、隣接するデータがアクセス対象となる空間的局所性持ちながら繰り返し実行することで時間軸上で局在していると言えるので、この局所性を時間的局所性(Temporal Locality)と言う。
命令により指定されるデータについても、データメモリアドレス値と時間軸上での局在性から空間的局所性と時間的局所性を持つ。従って、プログラムはそれぞれ固有の局所性を持つ。制御フローの変更も先に説明した様にプロセッサ内で分岐条件を保持するレジスタがあり、データ依存性(後述)同様な特性を持ち、そのレジスタ値に依存しており、制御依存している。
命令やデータキャッシュメモリは繰り返し読み書きする命令例やデータ列に対して、メモリ上で連続している命令列やデータ列に対して時間的局所性と空間的局所性を利用している典型的な例である。 - 依存性(Dependencies)
前述した様にソフトウェア・プログラムは時系列の記述(逐次実行性)を前提としており、同時に複数の命令を実行した場合、誤った動作をする可能性がある。図2.5(a)は3つのステートメントで構成されたごく小規模なプログラム片であり、この図2.5(a)を使用してアルゴリズムと逐次実行の関係を説明する。プログラムは上から下への順で実行されることを前提に記述しており、この3つのステートメント(プロセッサ上では3つの命令に相当する)を同時に実行すると何が発生するか確認する。
図2.5(b)の様に変数が代入操作の前に引数として参照されると、その演算は正しい結果を出力できない。このデータ(プログラム上ではデータあるいは変数であるが回路では信号に相当する)の流れによりアルゴリズムが形成される。この任意の変数について使用しているステートメント間の変数の関係を真のデータ依存性(True Data Dependency)という。ASICをはじめとする論理回路はその信号送信について真のデータ依存性で構成されている。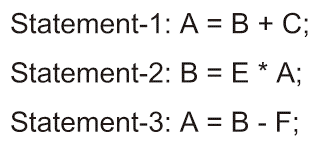 図2.5(a) Algorithm Example and Its Data Dependencies.: Program Fragment.
図2.5(a) Algorithm Example and Its Data Dependencies.: Program Fragment.
図2.5(c)では任意の変数について同時に複数の代入操作を試みようとしている。ハードウェア上ではメモリへの同時書き込み(代入操作)は優先順位を決めて記述している事もあり問題無いかもしれないが、ソフトウェア・プログラムの場合はどちらか一方が実行されてしまう不確定性があり、後続の書き込みを先に実行してしまう事も発生する(逐次実行性が保証されない)。この同時書き込み(代入操作)を試みている変数を使用したステートメント間の変数の関係を出力データ依存性(Output Data Dependency)という。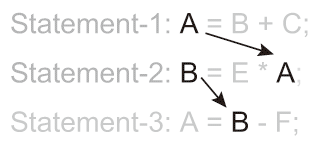 図2.5(b) Algorithm Example and Its Data Dependencies.: True Data Dependency.
図2.5(b) Algorithm Example and Its Data Dependencies.: True Data Dependency.
図2.5(d)は変数が引数として参照される前に代入操作を試みようとする例であり、明らかに逐次実行性に違反している。この逆方向のデータの流れを防ぐ必要があり、変数として使用している各ステートメント間のこの変数の関係を反データ依存性(Anti-Data Dependency)という。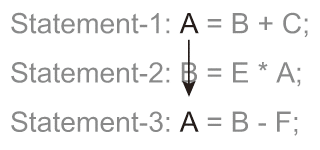 図2.5(c) Algorithm Example and Its Data Dependencies.: Output Data Dependency.
図2.5(c) Algorithm Example and Its Data Dependencies.: Output Data Dependency.
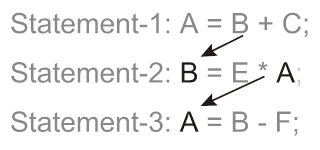 図2.5(d) Algorithm Example and Its Data Dependencies.: Anti-Data Dependency.
図2.5(d) Algorithm Example and Its Data Dependencies.: Anti-Data Dependency. - アルゴリズムの時空間への展開(Temporal and Spatial Operations)
図2.6は図2.6(a)の3つのステートメントをプロセッサ用のプログラムとして逐次実行する場合と、ASICの様なチップ上で演算を行う場合の時間軸上と空間への展開をそれぞれ示す。
図2.6(b)は時系列にする事により同時実行する演算器等のリソース量を抑えて少量のリソース構成で構成したプロセッサとして実装する場合に相当する(例えば一つの演算回路で加算と減算を行う)。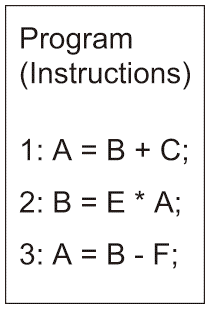 図2.6(a) Algorithm Example and Its Implementation Approaches.: Program.
図2.6(a) Algorithm Example and Its Implementation Approaches.: Program.
図2.6(c)は空間に各ステートメントの演算子をインスタンスとして複数実装して直接解決する演算回路として実装している。中間結果の変数はパイプラインレジスタとして実装するか、単に演算回路間の配線として実装する。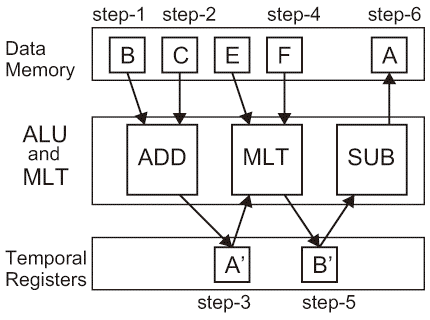 図2.6(b) Algorithm Example and Its Implementation Approaches.: Sequential Implementation.
図2.6(b) Algorithm Example and Its Implementation Approaches.: Sequential Implementation.
図2.6(b)において、逐次実行時にBとCがデータレイアウト時にメモリバンク上で衝突*3を起こしている場合、最初のステートメントのデータ参照に2サイクルを要する事を踏まえ、逐次実行する時の実行シーケンスは合計6ステップ必要な事が分かる。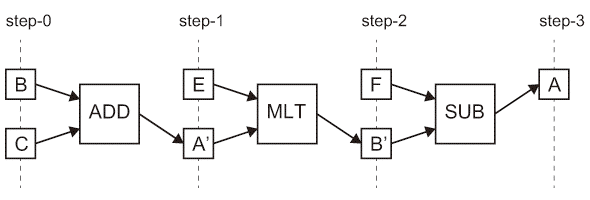 図2.6(c) Algorithm Example and Its Implementation Approaches.: Pipelined Parallel Implementation.
図2.6(c) Algorithm Example and Its Implementation Approaches.: Pipelined Parallel Implementation.
空間展開する場合はチップ上に変数を保持するメモリを自由に配置できる。変数A、B、C、E、そしてF全てチップ上に存在する場合のパイプライン型演算回路を図2.6(c)に示しており、3ステップで実行可能である。この様に逐次実行性と空間展開のバランス、つまりリソース量に応じたトレードオフを行いアーキテクチャを設計している。- *3 メモリユニットは一般に複数のメモリバンクで構成されている。 メモリバンクは同時に有限のメモリアクセス要求の数のみに応答可能であり、一つのメモリバンクにおいて同時に複数のアクセス要求が発生している状態をConfiict(衝突)という。
以上の事から一般に演算処理のアプローチは時系列計算(Temporal Computing)系と空間展開計算(Spatial Computing)系に分類できる。
- 時系列計算(Temporal Computing)
時間軸上で演算を行うことで演算回路を(時間)共有する。演算回路数を抑えられる反面、全体の演算に要する遅延時間は長くなる。 - 空間展開計算(Spatial Computing)
特定のデータフローグラフを空間上に展開して演算を行う。全体として演算遅延時間は短くなる反面、演算回路数は多くなる。
機械学習ハードウェアの場合、そのハードウェアリソース量が許容可能なネットワークモデルの規模を制限する。一般的なネットワークモデルを処理する場合、パラメータセットは相対的に大きすぎてチップ上に乗らない。従って大量にある有限のリソース量に合わせて、空間展開処理系では特にパラメータセットや入出力ベクトルといったデータセットを分割してチップに入出力する必要が発生する。データの入出力は演算までの待ち時間の発生と入出力経路上でのエネルギー消費の発生を意味する。後述するが一番エネルギーを消費するのはメモリアクセスであり、数百クロックサイクルとアクセス遅延がかなり大きいので性能とエネルギー効率の両面で向上が律速する要因となっている。
この事実から、ハードウェア性能を向上させるためには分割された複数のサブデータセットについて、チップ内外のメモリユニットへの転送回数と転送データサイズを最小限にする必要がある。


2.2.2 半導体設計時の制約
- 実装制約(Implementation Constraint)
- 配線遅延とエネルギー消費(Wire-Delay and Energy Consumption)
半導体プロセス技術の進歩により設計空間は広がっているが、配線幅の縮小により配線抵抗が大きくなっている(配線抵抗は配線断面積に反比例する)。90年台後半にはトランジスタ上の遅延より配線遅延が回路の最長経路遅延時間を支配するようになった【67】。設計空間の拡大に伴って実装する回路数は多くなり、各回路間の配線数は増加し(例えば完全網ではO(N2)である)、また回路間の配線遅延時間も長くなりやすい。そこで、回路間で直接配線するのではなく、チップ上の回路間でパケットルーティングする方法が検討され、現在ではチップ上のネットワーク(NoC; Networks-on-Chip)が利用されるようになっている【68】。
また、(動的)消費電力Pは下記のように表すことができる。
f、V、C、Aはそれぞれクロック周波数、動作電圧、チップの持つ静電容量、そしてチップ上のアクティブなトランジスタ数の割合である。チップはこの消費電力Pの分だけエネルギーを消費し発熱する。式2.1はトランジスタ上での消費電力を示しており、配線上でのエネルギー消費を考慮していない。P ∝ f × V2 × C × A式2.1
マイクロプロセッサの場合、クロック周波数(f)を上げるためにプロセッサのパイプライン段数を増やすと、その増加に伴い中間処理信号を保持するためのレジスタ数が急激に増加し消費電力はその分増加する【69】。また、分岐予測が外れた際のペナルティーもパイプライン段数だけ増加するので、多段パイプラインプロセッサの分岐予測精度が低ければ消費電力と性能が共に悪化しやすい【70】。
式2.1は半導体プロセスをスケーリングしても機能していた(Dennard's Scalingという【71】)が、半導体プロセスの縮小に伴いトランジスタでのリーク電流が増加して、動作電圧(V)は半導体プロセスの縮小率に反比例しなくなっている。半導体プロセスが縮小しても動作電圧(V)は低くならない。従って設計上、一定の消費電力枠の下ではクロック周波数(f)を下げるか、トランジスタ数を増やした場合チップ上のトランジスタ数に占める同時に動作するトランジスタ数の割合(つまりアクティブにできるトランジスタ数の割合(A))を下げる必要がある。図2.1(b)に示すように 2000年以降、クロック周波数(f)を上げられなくなっているのは発熱、つまり消費エネルギーの増加に起因している。この半導体プロセスのスケーリングと設計空間のスケーリング上のトレードオフ問題(ダークシリコン問題という【72】)に対して、消費電力に見合った回路の複雑さと配線遅延を考慮した回路設計が求められ、性能と消費電力の間でバランスのとれた効率の良いアーキテクチャ設計が求められる様になっている。
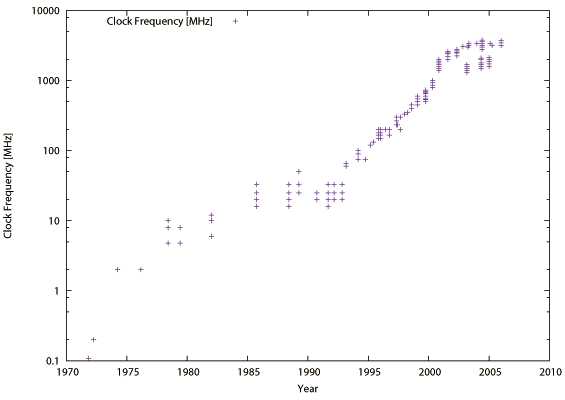 図2.1(b) History of Intel Microprocessors.: Clock Frequency.
図2.1(b) History of Intel Microprocessors.: Clock Frequency. - トランジスタ数とI/O数(The Number of Transistors and I/Os)
図2.7は実際のチップとして実装する際の物理的リソース量の制約であるトランジスタ数とI/Oピン数を示す。図2.7(a)はインテル以外も含む過去のマイクロプロセッサ実装に要したトランジスタ数である。これを見ると半導体プロセスの定期的な向上を示すムーアの法則に従っている事が分かる。
対して図2.7(b)は Xilinx のシングルチップ FPGA のユーザー定義が可能なIOB(I/O Block)の数だが、(ローエンドを含まないプロダクト・シリーズのプロットであり、時系列のプロットでない)ランダムロジックを載せたいFPGAでも1000ピン程度で停滞し、現時点で2000ピンを超えていない。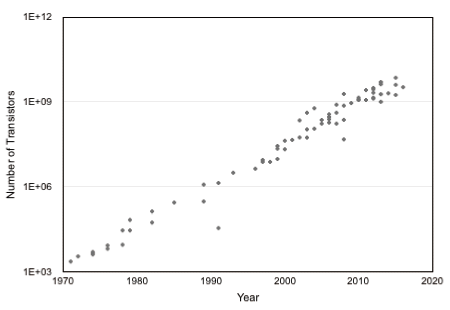 図2.7(a) History of Compositions.: Number of Transistors in Microprocessors.
図2.7(a) History of Compositions.: Number of Transistors in Microprocessors.
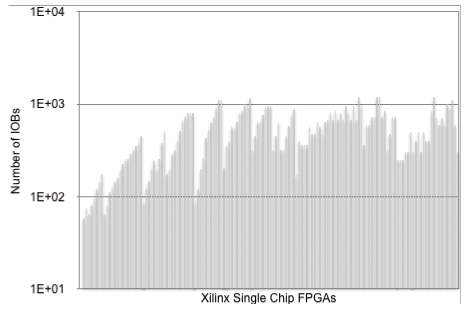 図2.7(b) History of Compositions.: Number of IOBs in Xilinx Single Chip FPGAs.
図2.7(b) History of Compositions.: Number of IOBs in Xilinx Single Chip FPGAs. - メモリとバンド幅ヒエラルキー(Memory and Bandwidth Hierarchy)
任意の変数をストアしているメモリへアクセスが集中する事がある。書き込みの集中(Fan-in)と参照の集中(Fan-out)が存在し、これを軽減するためにメモリの階層化を設けている。従来の計算機においてメモリの階層化はメモリアクセスの遅延問題【73】だけでなくこの目的でも利用されている。別チップとして存在しているメモリアクセス遅延の大きい外部メモリへの対応や、チップ上であれば自由にトランジスタを配置配線が可能であり、メモリブロックを自由に実装できるので一般にメモリを利用した階層(ヒエラルキー)構造を採用している。メモリへの集中負荷を避けるために演算回路の近傍には潤沢な配線を使用して広帯域幅を持たせてメモリ階層が下がる程、帯域幅を低くするトレードオフを実施している。
- 配線遅延とエネルギー消費(Wire-Delay and Energy Consumption)
- モジュール構造化と量産効果
ハードウェアについて特定機能の回路をモジュールとして扱える様に記述する事で、そのモジュール化した回路記述をソフトウェア・プログラムの関数同様にインスタンスとして使用する事ができる。プログラム同様にインターフェイス(引数と戻り値)に加えて、そのインターフェイスに基づいた関数の動作に必要なタイミングを定義する事でハードウェアのモジュール化が可能になっている。
複数の同じ回路、例えばメモリといった回路は大量に生産する事で、NREコストと実装コストを償却する事が容易であり、大量生産がもたらす量産効果によりチップの価格を低く設定する事ができ、結果として広く利用されやすくなる。利用が進めばさらに量産されるので好循環が生まれる。従って汎用製品はこの循環に乗りやすく、汎用製品の大量生産と低価格化に寄与している。 - Makimoto's Wave
Makimoto's Wave【74】によると、特定の新規アプリケーションからの処理性能要求に対して汎用プロセッサではその要求を満たせないのでASIC実装の専用化の方向へ揺れ、その後汎用プロセッサが技術をキャッチアップして要求を満たす汎用プロセッサに改良する事で再び利用者の利便性(Usability)を志向した汎用化の方向へ揺り戻す、という専用性と汎用性の間の振り子が存在する。
元々アプリケーションは利用者の問題解決のためのアルゴリズムであり、汎用と専用とは次元が違う話である。汎用化と専用化はアプリケーション実装上のトレードオフ問題であり、アプリケーションを設計する上での制約範囲内の最適化という点でどちらも機能している。市場立ち上がり時の性能要求に汎用プロセッサが応えられない(アルゴリズムの持つ特性にプロセッサアーキテクチャが合っていない)というだけである。GPUはデータ並列性のあるアプリケーション専用であり、FPGAはアプリケーションに合わせて最適化可能である。プロセッサ自身の性能の鈍化によりアプリケーションからの要求に対応しにくくなっており、GPUとFPGAに汎用計算機への導入の機会を与えている。
今後プロセッサはアルゴリズムの持つ特性に合わせられなくなるので、汎用化と専用化の振り子はその中間地点で止まる。そして、プログラム性を最適化に利用するのである。
■
次回は、「第2章 従来のアーキテクチャ、2.3 ハードウェア実装のまとめ」を転載します。
【参考文献】
- 【67】 D. Matzke. Will physical scalability sabotage performance gains? Computer, 30(9):37-39, September 1997.
- 【68】 W. J. Dally and B. Towles. Route packets, not wires: on-chip interconnection networks. In Design Automation Conference, 2001. Proceedings, pages 684-689, 2001.
- 【69】 John Paul Shen and Mikko H. Lipasti. Modern Processor Design: Fundamentals of Superscalar Processors. McGraw-Hill, beta edition, 2003.
- 【70】 Viji Srinivasan, David Brooks, Michael Gschwind, Pradip Bose, Victor Zyuban, Philip N. Strenski, and Philip G. Emma. Optimizing Pipelines for Power and Performance. In Proceedings of the 35th Annual ACM/IEEE International Symposiumon Microarchitecture, MICRO 35, pages 333-344, Los Alamitos, CA, USA, 2002.IEEE Computer Society Press.
- 【71】 M. Bohr. A 30 Year Retrospective on Dennard's MOSFET Scaling Paper. IEEE Solid-State Circuits Society Newsletter, 12(1):11-13, Winter 2007.
- 【72】 Hadi Esmaeilzadeh, Emily Blem, Renee St. Amant, Karthikeyan Sankaralingam, and Doug Burger. Dark Silicon and the End of Multicore Scaling. In Proceedings of the 38th Annual International Symposium on Computer Architecture, ISCA '11, pages 365-376, New York, NY, USA, 2011. ACM.
- 【73】 Doug Burger, James R. Goodman, and Alain Kägi. Memory Bandwidth Limitations of Future Microprocessors. SIGARCH Comput. Archit. News, 24(2):78-89, May 1996.
- 【74】 T. Makimoto. The hot decade of field programmable technologies. In 2002 IEEE International Conference on Field-Programmable Technology, 2002. (FPT). Proceedings., pages 3-6, December 2002.
※以下では、本稿の前後を合わせて5回分(第3回~第7回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
3. 第4次産業革命とは? 機械学習とブロックチェーンの役割
機械学習の新技術活用は第4次産業革命と呼ばれるが、その意味を説明。さらに、機械学習がデータ処理系であれば手続き処理系に相当するブロックチェーンについても概説する。
4. マイクロプロセッサからGPU/FPGAの利用へ ― 機械学習ハードウェア実装に関する時代変遷
計算機システムのハードウェア実装では、従来の主要要素であるマイクロプロセッサの性能向上が停滞してきたことから、GPUやFPGAが採用されるように時代が変遷してきた。その内容について概説する。
5. 【現在、表示中】≫ 機械学習ハードウェアの基礎知識: 特定用途向け集積回路「ASIC」
特定アプリケーションに特化した回路を集積する方法であるASICについて概説。アプリケーションを表現するアルゴリズムのソフトウェア実装とASIC実装を比較しながらASIC実装の特徴と制約を説明する。
6. 機械学習のハードウェア化の歴史と、深層学習の登場
1980年代~現在まで、機械学習のハードウェア実装の歴史を振り返る。計算機アーキテクチャの行き詰まりと深層学習の登場により、機械学習ハードウェアの研究が進んできたことを紹介する。
7. 機械学習のニューロモルフィック・コンピューティング・モデル
機械学習ハードウェアの「ニューロモルフィック・コンピューティング」(前者)と「ニューラル・ネットワーク」という大分類のうち、脳の構造と神経細胞(ニューロン)発火の仕組みを模倣した前者のモデルを説明する。