
書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(9)
機械学習ハードウェアとは? 実装基盤となるメニーコアプロセッサ/DSP/GPU/FPGAのアーキテクチャ概説
機械学習ハードウェアとは、設計開発した機械学習モデルを実行するハードウェアプラットフォームのことだ。その実装プラットフォームとなる「CPUを含むメニーコアプロセッサ」「DSP」「GPU」「FPGA」のアーキテクチャについて概説する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「第3章 機械学習と実装方法、3.2 ニューラルネットワーク」を転載しました。今回は、「第4章 機械学習ハードウェア、4.1 実装プラットフォーム」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
第4章 機械学習ハードウェア
第4章は設計開発した機械学習モデルを実行するハードウェアプラットフォームである、機械学習ハードウェアとその性能向上方法を説明する。
初めにその実現されたプラットフォームである、CPUを含むメニーコアプロセッサ、DSP、GPU、FPGAのアーキテクチャを説明する。ここでいうアーキテクチャはブロックダイアグラムレベルでの構造を指し、主要なデータの流れも示している。
次にプラットフォームの利用者が開発した機械学習モデルが実行される際のハードウェアとしての性能指標を説明する。
最後に、機械学習ハードウェアでネットワークモデルを効率良く高速処理あるいは低消費エネルギーで実行するために用いられる主な方法を説明する。モデルに制約を課すモデル最適化、パラメータセット全体の数を削減させるモデル圧縮、各パラメータのデータサイズを削減するパラメータ圧縮、データ全体の符号化により圧縮・伸長する符号化、データの再利用性を向上させて無駄なデータアクセスを削減する方法、そしてゼロ値の際に発生する無駄な演算を削減するゼロスキッピング演算を取り上げる。
4.1 実装プラットフォーム
4.1.1 メニーコアプロセッサ(Many-Core Processors)
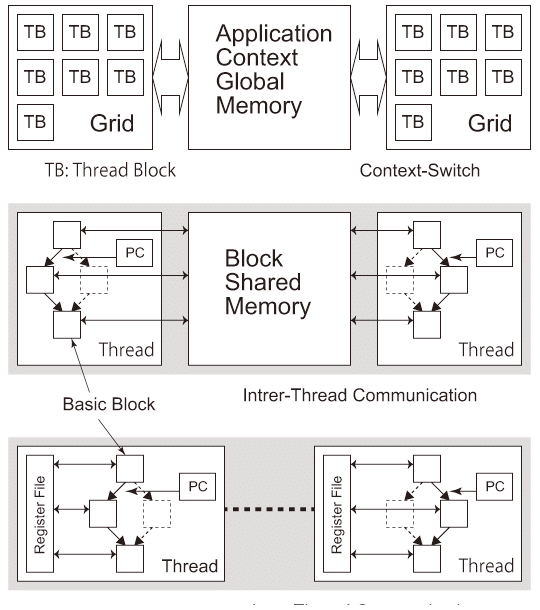
メニーコアプロセッサは、チップ上に複数のプロセッサコアを実装したチップ・マルチプロセッサ(CMP; Chip Multi-Processor)の事である。図4.1(a)は4 × 4の二次元メッシュトポロジで構成されたメニーコアプロセッサを示す。コア(図中“C”部)はルータ(図中“R”部)に接続され、ルータ経由で他のコアや外部と通信を行う【97】。
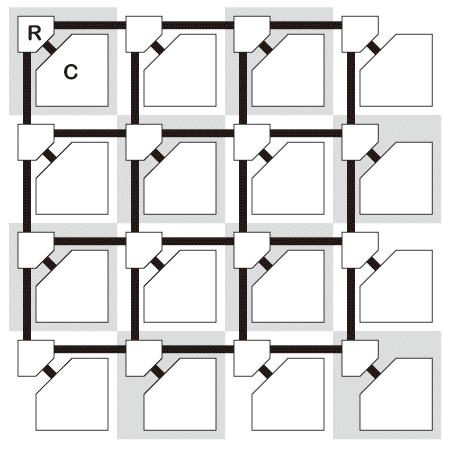
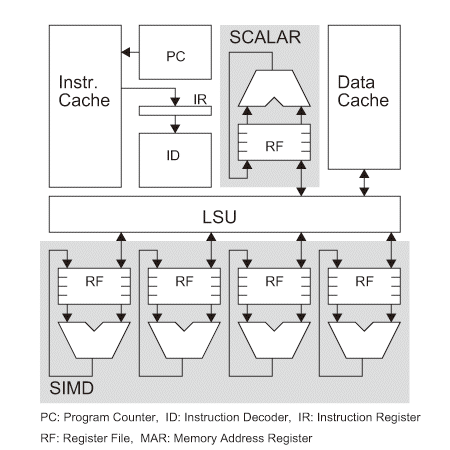
図4.1(b)はプロセッサコアの基本構成を示す。最近のコアは従来の演算ユニット(SCALAR)に加えて、同じ演算を同時並列に行うSIMD(Single Instruction stream Multiple Data stream)ユニットを持ち、データの並列処理能力を向上させている【98】。基本的に、従来のプロセッサで使用している開発言語と開発環境が利用できる。プロセス間通信とコヒーレンス*7の方法で2種類に分類できる。
- *7 データの一意性の事。 ソフトウェア・プログラムが扱う一意の変数が複数箇所に存在し得る場合、複数箇所にあるその変数の値が一意的あることを指す。
- Shared Memory:Implicit Messaging
コアの間でメモリアドレス空間を共有する共有メモリ型メニーコアプロセッサでは、プログラム開発時にプロセス間通信を意識して開発する必要はないが、プロセス間での共有変数に対する排他制御(プロセス間で同期を取る仕組み)やコヒーレンスを保つような工夫が必要である。そこで現在はTransactional Memoryという手法を実装して、投機的に排他制御(Lock)を行う方法が利用されている【99】。 - Message Passing:Distributed Memory
一般に各コアが独自のメモリアドレス空間を持つ分散メモリ型メニーコアプロセッサは、コアの間で変数を共有しないでメッセージの形で通信するメッセージパッシング型である。プロセス間通信を定義したMPI(Message Passing Interface【100】)などのライブラリをソフトウェア・プログラム上で利用して、明示的にプロセス間通信を指示して通信を行う。メッセージの送受信を基にしており変数を共有しないので、プロセス間でコヒーレンスや同期をとる機構は必要ない。
共有メモリ型とメッセージパッシング型の比較も研究されている【101】。メニーコアプロセッサは、ソフトウェア・プログラムとそれが使用するデータを各コアに乗るサイズ(Working-setと呼ぶ【102】)に細分化し、さらにコアの外への余分なメモリアクセス頻度を抑えるためにキャッシュメモリサイズを意識して分割する必要がある。
4.1.2 Digital Signal Processors
図4.1(c)はDigital Signal Processor(DSP)の基本構成を示す。DSPは演算を行う実行ユニット(EXU)を信号処理で利用されるMAC(Multiply-Accumulate)演算に特化している。繰り返し同じ処理を行うことが多いので、分岐命令ではなくハードウェアループ命令により対応している(図4.1(c)中 Hw-Loop 部)。従って分岐予測ユニットは持たないのが一般である。
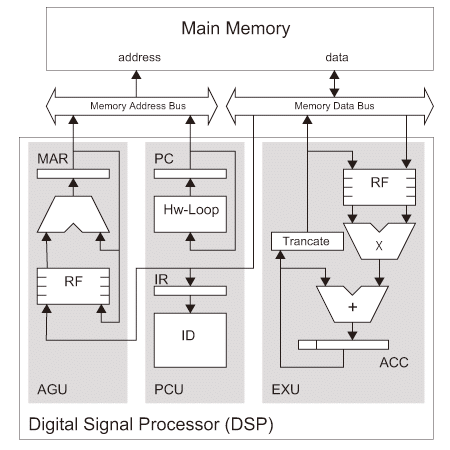
また、外部メモリへのデータアクセスにもパターンがあるので、アドレス生成ユニット(AGU)を設けてデータアクセス時のアドレスを生成するようにしている。初期は整数演算と固定小数点演算のみに対応していたが、後に浮動小数点演算にも対応している【103】。また当初アセンブリ言語によるソフトウェア開発が主流であったがコンパイラのサポートによりC言語での開発も可能になっている。
4.1.3 GPUs; Graphics Processing Units
当初グラフィックスハードウェアはグラフィックス処理に特化し固定されたパイプライン構成のハードウェアだった。しかしバーテックスやピクセル処理等の機能別にプログラム可能なプロセッサの構成にする事で実行するアルゴリズムを柔軟に構成可能になり、グラフィックス・アルゴリズム開発側も自社開発アルゴリズムをプログラムとして実装できるようになった【104】。このGraphics Processing Unit(GPU)は同じプログラム(Thread、スレッド)で複数のデータを並列に処理するSIMD方式が基本だった。
グラフィックスのワークロードはバーテックスとピクセル処理の間でバランスが取れておらず、非効率になり易い。NVIDIA社のCUDA(Compute Uni ed Device Architecture)パラレルプログラミングモデルはバーテックスとピクセル処理を同一のプロセッサアーキテクチャで実行することで、動的負荷バランス(dynamic load balancing)を可能にした【105】。これにより高速かつ効率的なプロセッサの開発に集約できた。NVIDIA社のGPUはSM(Streaming Multi-processor)と呼ぶマルチプロセッサ単位でSM内にある複数のSP(Streaming Processor)と呼ぶスーパースカラプロセッサで構成されており(ベクトル演算型プロセッサではない)、従来のコンパイラを利用可能かつ相対的に簡素なスケジューリングで十分なスカラ演算を行う。
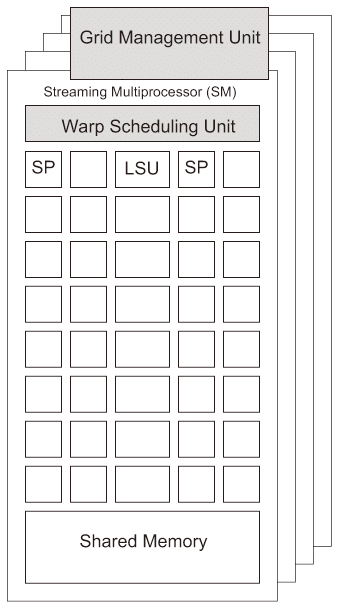
シェーディングやバーテックス処理等、同じタイプのスレッド*8は、thread blockと呼ぶ単位にまとめて管理される。SMコントローラはthread block中warpとよぶ最大32スレッドの集合で各スレッドを各SPに割り当てる。SM中の各スレッドは個々の命令アドレスとレジスタ状態を持ち独立して実行される。つまり、thread block内のスレッドは同じプログラムであるが、その制御フローは個別である。また、バリア命令をサポートしており、スレッド間の同期がとれるようにしている。
- *8 プログラムの実行単位であるプロセスを細分化した、プロセスの状態情報を共有するプログラムの最小単位を一般にスレッドと呼ぶ。
NVIDIA社では同じ命令列で構成された複数のスレッドがそれぞれ個別に実行するこの仕組みをSIMT(Single Instruction, Multiple Threads)と呼んでいる。SIMT方式により、プログラマは最大warp数といったSIMTを基にしたハードウェア構成を意識する事なくプログラミングが可能になっている。GPUプログラムはGridと呼ぶ複数のthread block単位で管理し、一つのthread blockを一つのSMへ割り当て、SMはthread blockのスレッドと個々のスレッドのレジスタステートを各SPへ割り当て、各SPは同じ命令列を個別の制御フローで実行する。
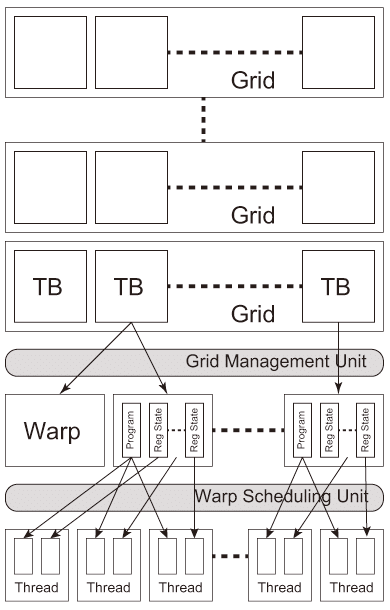
さらに最近ではキャッシュメモリを増強してメモリアクセス周りを強化したり、順不同(Out-of-Order)でのthread block実行のサポート、warpスケジューラの多重化、スレッド切り替え(context-switching)を高速化している【106】【107】。2016年、積層型メモリであるHBM2(High Bandwidth Memory)が採用され、深層学習でよく使用する半精度浮動小数点ユニットなどを実装したPascalアーキテクチャが発表された【108】。HBM2は帯域/消費電力比の改善と実装面積の最小化に寄与している。
4.1.4 FPGAs; Field-Programmable Gate Arrays
図4.3(a)はSRAMを回路の構成データを保持する記憶素子としたField-Programmable Gate Array(FPGA)の基本アーキテクチャを示す【109】。
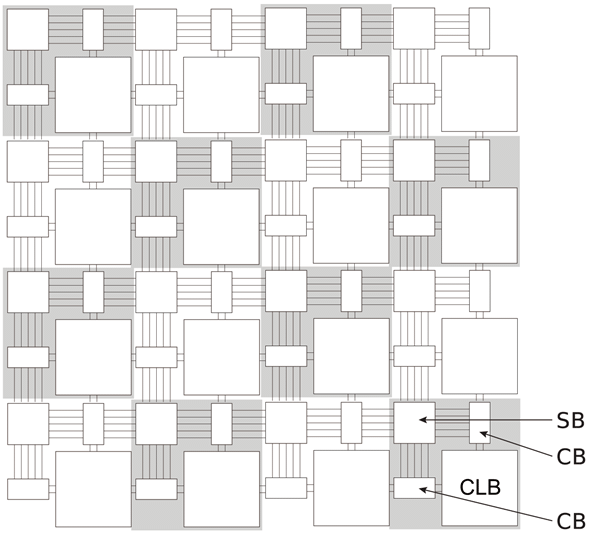
論理回路の組み合わせ回路を構成するための回路(CLB; Configurable Logic Block)、CLB間を接続する相互接続網であるCB(Connection Block)とSB(Switch Block)で構成される。CLBと複数のCB、SBをまとめて一つのタイルを作り、このタイルを並べて全体を構成する。ここでは利用者が設計した回路をユーザー回路と呼ぶ事にしてFPGA自身の回路と区別する。
CLBはK個の1-bit入力の真理値表に相当し、図4.3(b)に示すように一般にLUT(LookUp Table)と呼ぶマルチプレクサで構成されている【110】【111】。
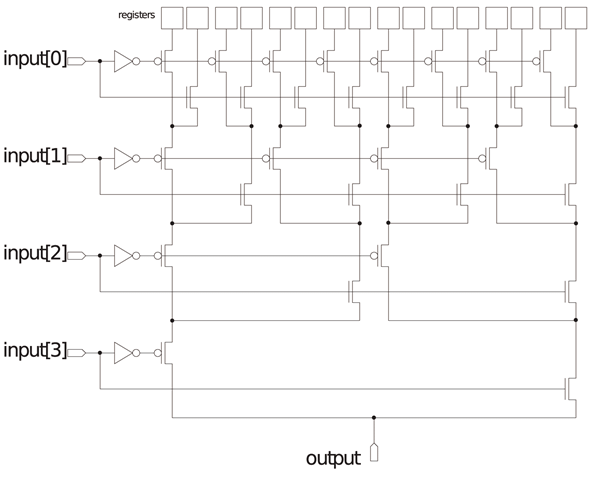
従ってLUTはK-bitの入力から2K個の1bitレジスタのデータを選択する。LUTの出力と前クロックサイクルでの出力値を保持するレジスタ(retiming registerと言う)から選択できるようになっている(図4.3(c)参照)。
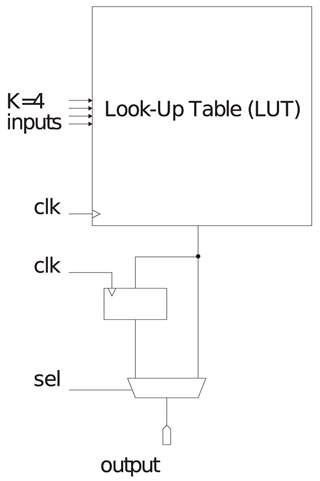
Retiming registerの値をユーザー回路にフィードバックすることで有限状態機械(FSM; Finite State Machine)等のユーザー回路を実装できるようにしている。CLBの入出力は相互接続網の配線にCBを経由して接続されており、横方向の配線は縦方向に、縦方向の配線は横方向にSBを経由して方向転換する。複数の配線はトラックを構成し、複数種類の配線長で構成されたトラックがあり、信号の送信先までの長さに合った配線を利用する事で配線の使用効率を上げ、かつ無駄に配線遅延が発生しないようにしている(この方法をChannel Segmentation Distributionと言う【109】)。Virtexアーキテクチャ以降ではこのタイル型アーキテクチャを改良し、タイルが構成する行列についてCLB、DSP、RAMブロックといった複数の種類の内一つの要素で構成した列を用意して適宜並べるレイアウトを行っている。
図4.4(a)はXilinxのシングルチップFPGA製品の持つLUT数を、一番左をXC2000、一番右をVirtex7としてプロットしている(時間軸のプロットではない事に注意が必要である。またSpartan等のローエンド品は含まない)。
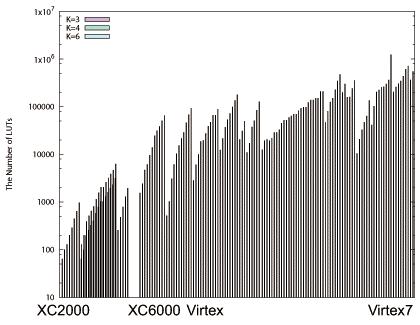
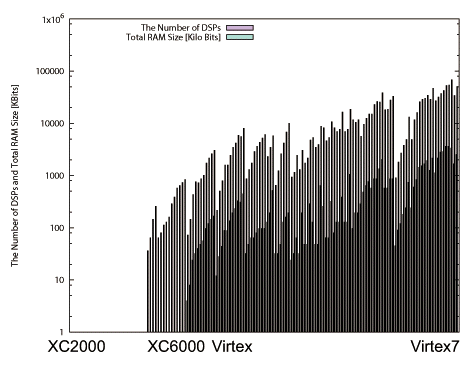
XC4000まで半導体プロセスの向上に伴い、LUT数を増加させ、構成できるランダムロジックの規模を大きくしている。図の途中LUTがないのはLUTではなくマルチプレクサで構成したCLBを採用しているXC6000シリーズである。その後Virtexアーキテクチャになると、LUTの数をそれほど増加させず、図4.4(b)に示すようにMemory Blockを大量に実装することで外部メモリへのアクセスを減らし、かつ低遅延で同時並行にメモリアクセスする事で高速なデータ並列処理を可能にした。さらに、積算器と加算器で構成されるDSPと呼ぶ演算回路を大量に実装する事で(図4.4(b)参照)、通信処理アプリケーション等で広く使用されるデジタル信号処理に対応させ、LUTでユーザー回路を構成する時よりも高クロック周波数でかつ小実装面積で実装可能にしている。
FPGA上でのハードウェア開発フローは、ASIC同様にRTL(Register-Transfer Level)コーディングとシミュレーションによる動作検証を繰り返し、その後に論理合成、対象FPGA向けに配置配線、最後に構成データ生成、構成データをFPGAにダウンロードして実動作の検証を繰り返し行う。最近ではC言語といったソフトウェア開発で一般的なプログラミング言語でハードウェア開発が可能になってきている。C言語といった言語でアルゴリズムを作成したソフトウェア・プログラムをハードウェア記述言語(HDL; Hardware Description Language)に変換するツールが研究開発されているためである【112】【113】。
■
「第4章 機械学習ハードウェア」の「4.2 性能指標」~「第5章 機械学習モデルの開発」「第6章 ハードウェア実装の事例」「第7章 ハードウェア実装の要点」「第8章 結論」は転載対象外となっています。ご興味がある方は、ぜひご購入(Amazon.co.jpのページもしくは出版元のページ)をご検討ください。/p>
次回以降は付録の中から、「付録A 深層学習の基本、A.1 数式モデル」を転載します。
【参考文献】
- 【97】 E. Waingold, M. Taylor, D. Srikrishna, V. Sarkar, W. Lee, V. Lee, J. Kim, M. Frank, P. Finch, R. Barua, J. Babb, S. Amarasinghe, and A. Agarwal. Baring it all to software: Raw machines. Computer, 30(9):86-93, Sep 1997.
- 【98】 A. Sodani, R. Gramunt, J. Corbal, H. S. Kim, K. Vinod, S. Chinthamani, S. Hutsell, R. Agarwal, and Y. C. Liu. Knights Landing: Second-Generation Intel Xeon Phi Product. IEEE Micro, 36(2):34-46, March 2016.
- 【99】 Maurice Herlihy and J. Eliot B. Moss. Transactional Memory: Architectural Support for Lock-free Data Structures. SIGARCH Comput. Archit. News, 21(2):289-300, May 1993.
- 【100】 MPI. The Message Passing Interface (MPI) standard.
- 【101】 A. C. Klaiber and H. M. Levy. A Comparison of Message Passing and Shared Memory Architectures for Data Parallel Programs. In Proceedings of the 21st Annual International Symposium on Computer Architecture, ISCA '94, pages 94-105, LosAlamitos, CA, USA, 1994. IEEE Computer Society Press.
- 【102】 Peter J. Denning. The Working Set Model for Program Behavior. Commun. ACM, 26(1):43-48, January 1983.
- 【103】 First-Generation TM320 User's Guide. Texas Instruments Inc. 1988.
- 【104】 J. Montrym and H. Moreton. The GeForce 6800. IEEE Micro, 25(2):41-51, March 2005.
- 【105】 E. Lindholm, J. Nickolls, S. Oberman, and J. Montrym. NVIDIA Tesla: A Unified Graphics and Computing Architecture. IEEE Micro, 28(2):39-55, March 2008.
- 【106】 NVIDIA’s Next Generation CUDA Compute Architecture:Fermi. https://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf, 2009. White Paper.
- 【107】 NVIDIA’s Next Generation CUDA Compute Architecture:Kepler GK110. https://www.nvidia.com/content/PDF/kepler/NVIDIA-Kepler-GK110-Architecture-Whitepaper.pdf, 2012. White Paper.
- 【108】 NVIDIA’s Next Generation CUDA Compute Architecture:Kepler GK110. http://www.nvidia.com/object/gpu-architecture.html#source=gss, 2016.
- 【109】(2) S. Brown, R. Francis, J. Rose, and Z. Vranesic. Field-Programmable Gate Arrays. Springer/Kluwer Academic Publishers. May 1992.
- 【110】 P. Chow, Soon Ong Seo, J. Rose, K. Chung, G. Paez-Monzon, and I. Rahardja. The design of a SRAM-based field-programmable gate array. I. Architecture. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 7(2):191-197, June 1999.
- 【111】 P. Chow, Soon Ong Seo, J. Rose, K. Chung, G. Paez-Monzon, and I. Rahardja. The design of a SRAM-based field-programmable gate array-Part II: Circuit design and layout. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 7(3):321-330, September 1999.
- 【112】 Andrew Canis, Jongsok Choi, Mark Aldham, Victor Zhang, Ahmed Kammoona, Jason H. Anderson, Stephen Brown, and Tomasz Czajkowski. LegUp: High-level Synthesis for FPGA-based Processor/Accelerator Systems. In Proceedings of the 19th ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA '11, pages 33-36, New York, NY, USA, 2011. ACM.
- 【113】 Vivado Design Suite - HLx Edition. https://www.xilinx.com/products/design-tools/vivado.html.
※以下では、本稿の前後を合わせて5回分(第7回~第11回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
7. 機械学習のニューロモルフィック・コンピューティング・モデル
機械学習ハードウェアの「ニューロモルフィック・コンピューティング」(前者)と「ニューラル・ネットワーク」という大分類のうち、脳の構造と神経細胞(ニューロン)発火の仕組みを模倣した前者のモデルを説明する。
8. ディープラーニングを含むニューラルネットワーク・モデルと、そのハードウェア実装
一般的なニューラルネットワークモデルとディープラーニング(深層学習)について紹介。さらにそのハードウェアを実装するための一般的な方法を説明する。
9. 【現在、表示中】≫ 機械学習ハードウェアとは? 実装基盤となるメニーコアプロセッサ/DSP/GPU/FPGAのアーキテクチャ概説
機械学習ハードウェアとは、設計開発した機械学習モデルを実行するハードウェアプラットフォームのことだ。その実装プラットフォームとなる「CPUを含むメニーコアプロセッサ」「DSP」「GPU」「FPGA」のアーキテクチャについて概説する。
10. ディープラーニング(深層学習)の基本: 数式モデル
ディープラーニング(深層学習)の一般的なネットワークモデルである「順伝播型ニューラルネットワーク」の、各ユニットにおける演算を表現する数式モデルを示しながら、その意味を説明する。
11. 機械学習ハードウェアモデル ― 深層学習の基本
深層学習における、パラメーター空間と順伝播・逆伝播演算の関係を説明。また、代表的な学習の最適化方法と、パラメーターの数値精度についても紹介する。