
書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(11)
機械学習ハードウェアモデル ― 深層学習の基本
深層学習における、パラメーター空間と順伝播・逆伝播演算の関係を説明。また、代表的な学習の最適化方法と、パラメーターの数値精度についても紹介する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「付録A 深層学習の基本、A.1 数式モデル」を転載しました。今回は、「A.2 機械学習ハードウェアモデル」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
A.2 機械学習ハードウェアモデル
A.2.1 パラメータ空間と順伝播・逆伝播演算の関係
図A.1は深層学習の任意の層lにおける、主に(J × I)構成のパラメータ空間とJ個の活性化関数で構成された順伝播と逆伝播処理に要する演算をデータレイアウトを中心に表現し、その入出力関係と各演算の関係を図示してる。
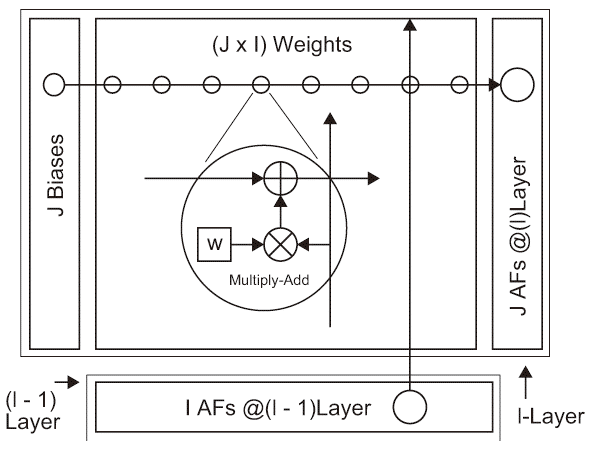
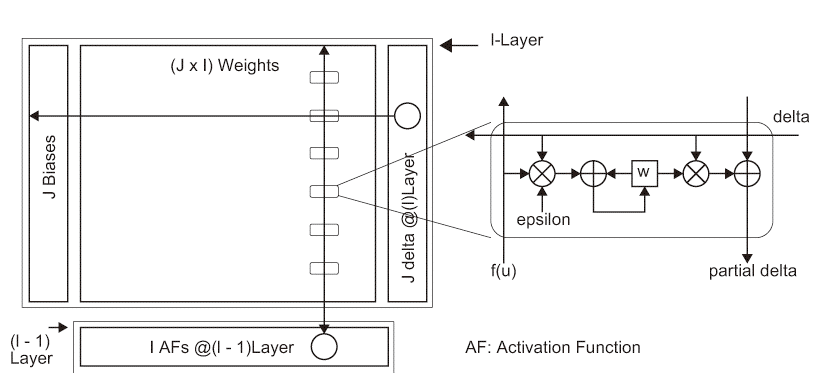
図A.1下に(l − 1)層のI個のユニットが並んでいて、その上にパラメータの主要要素である重みデータがJ × Iのマトリックス、その左側にパラメータの一種であるバイアスがJ × 1のベクトルとして並んでいる。そしてJ × Iの重みアレイの右側にJ × 1個の活性化関数がある。図A.1(a)は任意のl層における順伝播、図A.1(b)は任意のl層における逆伝播の演算に要するデータの入出力を示している。逆伝播時のδi(l − 1)は図A.1(b)中“partial delta”の最終出力値に式A.5の様にf ′i(l − 1)(ui(l − 1))を積算すれば得る
図A.1の通りに設計すれば順伝播型ニューラルネットワークの基本機能は実装できる(一般化にはさらにスパース接続制御とパイプラインレジスタの挿入が別途必要になる)。従って、最大3つのMAD(Multiply-Add)回路を重み用の演算回路として設計すれば順伝搬と逆伝播両方に対応した機械学習ハードウェアが開発できる。この回路を4つスパイラル状(循環状)に接続して、適宜パラメータ等を入出力してニューラルネットワークモデルを実行するこのユニットを“Spiral Network”と呼ぶ事にする。勿論、文字“W”の様に回路の接続をうねらせて4つ以上のこの回路の接続も可能である。4層分の順伝播と逆伝播の同時実行が可能であり、またオンライン学習以外のバッチ学習やミニバッチ学習にも対応可能である。
設計したSpiral Networkより、実行したいニューラルネットワークモデルのパラメータ空間が大きい場合のための仕組みと、誤差関数演算等を追加すればハードウェア単体としては大体完成である。前者の例として、重み用記憶素子をレジスタから複数のエントリで構成されたRAMに置き換える方法がある。アクティベーションに“層番号”と“パラメータ空間アドレス”を付与し、これらの組み合わせた値を重みRAMの読み出しアドレスとする。パラメータ空間アドレスは、実行したいネットワークモデルの持つパラメータ空間を設計したSpiral Networkの許容可能なパラメータ空間を単位として分割し、それぞれに固有の番号(アドレス)を付与したものである。
以上の事から分かる様に機械学習ハードウェア、特に深層学習用ハードウェアは基本的に単純な演算の集合であり、スループット等のハードウェア性能は有限なハードウェア上にパラメータ等のデータの供給をいかに効率良くできるかにより決まる。
A.2.2 学習の最適化
学習の最適化は盛んに研究されている。ここでは代表的な方法を簡単に紹介する。
- モメンタム(Momentum)
重みwji(l)の更新時に前回の更新量に係数αを積算した値を加えることで慣性的に更新するようにする項を式A.3に追加する。 - 重み減衰(Weight Decay)
前回の更新時の重みwji(l)に対して学習係数ϵと減衰させる係数λを積算して得る値を今回の更新時の正則項として使用する。つまり過剰な更新量にならないように調節するための項である。式A.3に減算の項として追加する。
A.2.3 パラメータの数値精度
パラメータの数値精度は単精度浮動小数点が一般的だったが、それほどの精度がなくても推論精度に強い影響を与えない事が報告されている【121】。特定の層で必要とされる最低限の精度は、その層の規模と前後の層との関係で異なることが考えられる。例えばFPGAのDSPを符号付き8bit積算器によるMAC演算を実装する検討【221】もあるが、それ以外のモデルにおいて精度が要求される場合もあるので、単に符号付き8bit積算器を実装しても一般的なニューラルネットワークモデルの推論性能と学習性能は保障されない。何より線形表現の符号付き8bit表現の積算器では、24bitの累算器だと最大256個のシナプスしか接続できないので用途が限定される*11。一般に符号付き8bitデータパスでの演算が可能な場合は、例えば量子化を事前に実施しているからであり単純に8bitデータパスの演算を実施しているわけではない。
- *11 積算器の後に配置される累算器の幅により最大シナプス数が決まる。何に使うか次第ではあるが、ドロップアウトを実施しているとしても下位層では一般に少なすぎる数で実用性があるかは疑問である。
- 16-bit Fixed-Point Number【122】
短い幅の固定小数点で懸念される事は、ごく小さい値を扱う際に桁数が足りずに桁落ちして値がゼロ値になる事である。16bitの固定小数点でも適切な丸め処理を行えば、単精度浮動小数点演算で実装した場合と同等な推論精度が得られる事が報告されている。研究報告では2つの丸め処理方法としてRound-to-NearestとStochastic Roundを提案し、後者の方法が単精度浮動小数点演算で実装した場合と同等な推論精度を実現した事を報告している。 - Dynamic Fixed-Point Number【222】
固定小数点は小数部の幅に合わせて積算と除算の後にそれぞれ右と左のシフト演算が必要だが、加減算は普通の加算回路で演算できる。この研究では整数部は任意の層のパラメータやベクトルが共通と仮定した上で、動的に小数部の幅を変えている。オーバーフロー率を計測しておき、それがパラメータやベクトルより小さい時に小数部を1bit増やして、2倍以上大きい時は小数部を1bit減らす事で動的に指数部を変える。順伝播と逆伝播時に小数部幅を10bit程度、パラメータ更新時に12bitとする事で、単精度と変わらない程度の誤差率を実現している。 - 8-bit Approximate Representation【223】
8bitのビットフィールド中で表現可能なパターン数は256種類であるが、線形にその全てを網羅する必要がない場合がある。この研究のデータフォーマットは、符号、指数部、仮数部で構成されている。仮数部の取り得るビットフィールドを動的に範囲を変える(Dynamic Range)事で、取り得る値の範囲を適宜変える試みである。仮数部の取り得る値の範囲を決めてその中心値から2分木で値を定義している。また、この2分木の取り得るレベルは指数部を表す連続したゼロ値の数次第である。この研究ではこのデータフォーマットを使用した演算を通常の数値演算回路で実装あるいは演算可能かどうかは触れていない。 - BinaryConnect【123】
Binary ConnectではStochastic Binarizationを提案している。重みなどのパラメータは実数であるが、それを順伝播と逆伝播の時にHardsigmoidにパラメータを入力し、得た値を0.5を境目に+1と−1の何れかの値として計算する。Hard sigmoid(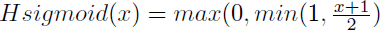 )の値が0.5以下の時−1、0.5より大きい時+1としている。パラメータ更新時には元の実数を用いてクリッピング処理をした上で更新する。これにより推論や学習時の内積演算に積算器は不要になるので、パラメータの符号を見て加算か減算を行う加算器(累算器)で十分になる。
)の値が0.5以下の時−1、0.5より大きい時+1としている。パラメータ更新時には元の実数を用いてクリッピング処理をした上で更新する。これにより推論や学習時の内積演算に積算器は不要になるので、パラメータの符号を見て加算か減算を行う加算器(累算器)で十分になる。 - BinaryNet【124】
Binary NetはBinary Connectと異なり、二進数値化の対象の値xの符号のみを見る。この時正数あるいはゼロ値の時+1、負数の時−1とする事で、積算は1bitのXNOR演算に置き換えられるので、通常必要な積算器を不要にする。これにより多くの内積演算を実装できるので高データ並列処理を可能にする。推論時に入力層では入力ベクトルのビット数に合わせたXNOR演算が必要だが、それ以降の層では単純にXNOR演算による内積演算で良い。推論と学習共に他にバッチ正規化も使用する。ベンチマークの範囲ではBinaryConnectよりテストエラー率は高めであるが、学習速度が速い。 - Binary-Weight-Networks【125】
Binary-Weight-NetworkはパラメータWをバイナリ値としたネットワークである。畳み込み演算はIW ≈ α(IB)、Bはバイナリ値−1,+1であり、αは近似用のスケール係数である。BはWの符号がある時−1それ以外を+1とし、αはノルム1の平均値(||W||l1/n、n = c × w × hについてc、w、そしてhはそれぞれチャネル数、フィルタの幅と高さである)とする。従ってα(IB)の各行はI各行をBを条件として加減算した後に、スケール係数を積算すれば得られる。2値化はBinaryNet同様に推論と学習時に実施して、パラメータの更新には使用しない。 - XNOR-Nets【125】
XNOR-NetはBinary-Weight-Networkからさらに(入力)ベクトルも2値化した方法である。入力値Iも符号を見て符号がある時−1それ以外を+1としI=−1,+1とする。その時の畳み込み演算はIW ≈ [sign(I) ⊛ sign(W)] ⊙ K ⊙ α、Kは重みフィルタ数を収めた行列、sign(I)は行列Iの符号を見て2値を生成する関数である。ここで⊛はsign(I)の行要素とsign(W)の各列要素とをXNOR演算後に加算する内積演算である。2値化はBinaryNet同様に推論と学習時に実施して、パラメータの更新には使用しない。 - Quantized Neural Networks【224】
BinaryNetやXNOR-Netは勾配計算は2値ではなく実数を使用している。これに対して、Quantized Neural Networkでは勾配計算も量子化を実施している。全体的に近似式を使用して処理を行っている。この研究では別研究で提案されたlogarithmic quantazation【225】を使用して量子化を行なっている。Logarithmic_quantazation(x, bitwidth)=Clip(AP2(x),minV, maxV)としている。ここで、AP2(x)はxの値に近い2の乗数値を表現していて、minVとmaxVは最小と最大の量子化範囲である。バッチ正規化もシフト演算を基にした近似式で行う。入力層の値sは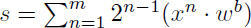 で計算する。mは入力値のビット幅であり、wbはkの要素を持つ1bitの重みのベクトルでああり、これとkの要素で構成される入力値の各ビット位置において内積を取り、最終的にmビット分累算した値に対してバッチ正規化した値を入力値とする。2値化に限定せず、多ビットへの量子化スケールにも対応している。
で計算する。mは入力値のビット幅であり、wbはkの要素を持つ1bitの重みのベクトルでああり、これとkの要素で構成される入力値の各ビット位置において内積を取り、最終的にmビット分累算した値に対してバッチ正規化した値を入力値とする。2値化に限定せず、多ビットへの量子化スケールにも対応している。
■
次回は、「付録A 深層学習の基本、A.3 深層学習と行列演算」を転載します。
【参考文献】
- 【121】 A. W. Savich, M. Moussa, and S. Areibi. The Impact of Arithmetic Representation on Implementing MLP-BP on FPGAs: A Study. IEEE Transactions on Neural Networks, 18(1):240-252, January 2007.
- 【122】 Suyog Gupta, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan. Deep learning with limited numerical precision. CoRR, abs/1502.02551, 392, 2015.
- 【123】 Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. BinaryConnect: Training Deep Neural Networks with binary weights during propagations. CoRR, abs/1511.00363, 2015.
- 【124】 Matthieu Courbariaux and Yoshua Bengio. BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1. CoRR, abs/1602.02830, 2016.
- 【125】(2) M. Rastegari, V. Ordonez, J. Redmon, and A. Farhadi. XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks. ArXiv e-prints, March 2016.
- 【221】 Yao Fu, Ephrem Wu, Ashish Sirasao, Sedny Attia, Kamran Khan, and Ralph Wittig. Deep Learning with INT8 Optimization on Xilinx Devices. https://www.xilinx.com/support/documentation/white_papers/wp486-deep-learning-int8.pdf, November 2016.
- 【222】 M. Courbariaux, Y. Bengio, and J.-P. David. Training deep neural networks with low precision multiplications. ArXiv e-prints, December 2014.
- 【223】 Tim Dettmers. 8-Bit Approximations for Parallelism in Deep Learning. CoRR, abs/1511.04561, 2015.
- 【224】 Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Quantized Neural Networks: Training Neural Networks with Low Precision Weights and Activations. CoRR, abs/1609.07061, 2016.
- 【225】 Daisuke Miyashita, Edward H. Lee, and Boris Murmann. Convolutional Neural Networks using Logarithmic Data Representation. CoRR, abs/1603.01025, 2016.
※以下では、本稿の前後を合わせて5回分(第9回~第13回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
9. 機械学習ハードウェアとは? 実装基盤となるメニーコアプロセッサ/DSP/GPU/FPGAのアーキテクチャ概説
機械学習ハードウェアとは、設計開発した機械学習モデルを実行するハードウェアプラットフォームのことだ。その実装プラットフォームとなる「CPUを含むメニーコアプロセッサ」「DSP」「GPU」「FPGA」のアーキテクチャについて概説する。
10. ディープラーニング(深層学習)の基本: 数式モデル
ディープラーニング(深層学習)の一般的なネットワークモデルである「順伝播型ニューラルネットワーク」の、各ユニットにおける演算を表現する数式モデルを示しながら、その意味を説明する。
11. 【現在、表示中】≫ 機械学習ハードウェアモデル ― 深層学習の基本
深層学習における、パラメーター空間と順伝播・逆伝播演算の関係を説明。また、代表的な学習の最適化方法と、パラメーターの数値精度についても紹介する。
13. ネットワークモデル開発時の課題 ― 深層学習の基本
訓練と交差検証で誤差率が高い場合は、バイアスが強い「未適応状態」もしくはバリアンスが強い「過適応状態」である。このバイアス・バリアンス問題の調整について概説。