
書籍転載:Thinking Machines ― 機械学習とそのハードウェア実装(3)
第4次産業革命とは? 機械学習とブロックチェーンの役割
機械学習の新技術活用は第4次産業革命と呼ばれるが、その意味を説明。さらに、機械学習がデータ処理系であれば手続き処理系に相当するブロックチェーンについても概説する。
前回は、書籍『Thinking Machines ― 機械学習とそのハードウェア実装』から「第1章 イントロダクション、1.3 学習と性能」を転載しました。今回は、「1.4 機械学習の位置づけ」を転載します。
書籍転載について

本コーナーは、インプレスR&D[Next Publishing]発行の書籍『Thinking Machines ― 機械学習とそのハードウェア実装』の中から、特にBuild Insiderの読者に有用だと考えられる項目を編集部が選び、同社の許可を得て転載したものです。
『Thinking Machines ― 機械学習とそのハードウェア実装』(Kindle電子書籍もしくはオンデマンドペーパーバック)の詳細や購入はAmazon.co.jpのページもしくは出版元のページをご覧ください。書籍全体の目次は連載INDEXページに掲載しています。
ご注意
本記事は、書籍の内容を改変することなく、そのまま転載したものです。このため用字用語の統一ルールなどはBuild Insiderのそれとは一致しません。あらかじめご了承ください。
■
1.4 機械学習の位置づけ
1.4.1 第4次産業革命(Industry4.0)
第4次産業革命(Industry4.0)と呼ばれる産業技術がその実現と応用に向けて積極的に研究開発されている。Industry4.0では、例えば工業では顧客のニーズの変化に応じて生産ラインを動的に変更し、材料や製品の在庫管理も踏まえ、顧客からの依頼から出荷まで一貫して最適化・改善を行う高効率な生産システムを情報技つつを利用して構築がすることであり、これまで3回あった産業革命に続く4度目の産業革命の位置付けである【49】。
ここではIndustry4.0を例に、機械学習と他分野との関連性を説明する事で機械学習の役割を簡単に説明する。まず、一般的な情報収集から利用・運用者の目的とする最終判断までの処理の流れについて層構造を利用して説明する。次に実際のIndustry4.0が適用される典型的な例である工場を例としてIndustry4.0を説明する。
Industry4.0は情報技術(IT; Information Technology)を基に自立した意思決定を支援する事が最大の目標であり、機械学習は収集している複数の種類の情報をまとめる役割がある。特に同時並行に複数の情報を逐次収集する必要がある場合、その大量の情報の中から利用側が必要としている相関関係を検知する事で、情報をまとめて分析するための支援を行う役割がある。
ここでいう利用側というのは人にとどまらない。動植物であったり、機械、物理的に存在するロボットやネットワーク上に存在するソフトウェア・ロボット(ボットという)であり、またそれらの集団組織や複合組織である。本書ではこれら有形無形をまとめて総体(Everything)と呼ぶことにする。表1.2はIndustry4.0を情報収集から意思決定支援まで、対象環境側を低層、意思決定側を高層として層構造で表している。
| 層構造 | 使用目的・処理内容 |
|---|---|
| Authorizing | 検知と予測情報に基づいた統計分析による意思決定支援。あるいは立案の実行 |
| Consolidating | 収集したデータ間の相関から特定事象の検知と予測。それに基づく立案 |
| Sampling | 対象環境から目的の情報を収集 |
- 情報収集(Sampling)
対象とする環境から情報を収集する最下位層である。物理的環境から実際にセンサーを使用して情報を収集したり、ネットワーク環境であるインターネットやイントラネットから情報を収集、総体の周辺環境、総体が利用する据え置き端末、総体に付随する携帯端末、そして総体内部環境からも情報を収集できる。 - 情報統合(Consolidating)
単一の情報収集、あるいは同時並行して収集した複数(種類)の情報について利用者が関心のある特定事象に対して相関を検知して近い将来の相関の変化を予測し、場合によっては立案等を行う層である。 - 意思決定(Authorizing)
検知した結果や予測結果に基づいた統計解析を行い、意思決定をするための根拠を作成する最上位層である。あるいは立案を基にそれを実行する層である。
Industry4.0は、適用する範囲によって物理的に広い物事から狭い世界の物事や、インターネット上の情報といった複合的な情報処理への利活用が考えられる。Sampling層はIoT(Internet of Thing)、IIoT(Industrial Internet of Thing)、IoE(Internet of Everything)等のクライアント(エッジ)側デバイスが該当する。Consolidating層は機械学習が該当し、Authorizing層はBig Data Analyticsが該当する。総体(Everything)が産業・加工用機械等やロボットの場合、支援情報に基づき自律的に意思決定して行動する場合もある。自動車といった移動体の自動運転がその典型的な例である。
図1.1(a)は典型的な層構造を使用したIndustry4.0の処理の流れと構成を示している。これを使用した生産・加工工場を例に、集中管理型と分散管理型システムを説明する。
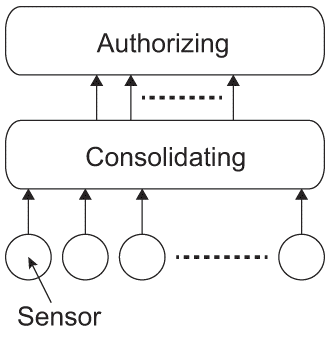
- 集中管理型工場(Centralized Factory)
図1.1(b)は情報収集、情報統合、意思決定の層で構成された集中管理型の工場モデルである。3つの層はそれぞれ、IoTクライアント(エッジデバイス)、機械学習システム、そして意思決定システムに相当し、全体としてのヒエラルキーを構成している。上位層は下位層から情報を収集し、各役割に従った処理を行う。情報収集層と情報統合層の間はイントラネットあるいいはインターネットである。
例えば、パイプライン型の工場において、各生産・加工ステージでの各要素について情報収集を行い、各ステージについて収集した要素情報に基づいて機械学習で状態を検証・認識し、各ステージの検証結果情報を取りまとめて状況判断・予測を行い複数のプランを立案する。意思決定層はそのプランに基づき今後の対策について生産目標を鑑みながら最良のプランを選択する最終判断を行う。最終判断に従い、各パイプラインステージでの各要素の更新量が決定され各ステージに反映させる生産過程の循環型最適化を行う。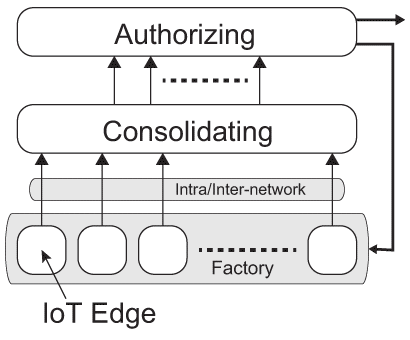 図1.1(b) IoT Based Factory Examples.: Centeralized Management Based Factory.
図1.1(b) IoT Based Factory Examples.: Centeralized Management Based Factory. - 自律分散型工場(Decentralized Factory)
図1.1(c)の(a)は分散管理型の工場モデルである。人やロボット等の作業員が複数存在し、各作業員は移動可能な場合もある。各作業員は、図1.1(c)の(b)の様な情報収集、情報統合、意思決定の層を構成する。作業員がロボットの場合、可動部等の情報についてセンサーを通して収集し、機械学習により今後の最終的な動作を複数立案し、意思決定層で他の近隣作業員の状況を含めたこの作業ロボットの動作を最終決定する(行動計画作成の実施)。従って、任意の作業員ロボットや人の動作が近隣の作業員と干渉し合う現象の発生が考えられる。
この干渉問題を抑えるために、個々のロボットは少なくとも隣接する作業員と作業について何らかのルールの定義が必要である。特に人が作業員として介在する工場においてはルールを全て把握した上での作業は困難なので、少なくとも人とロボットの近隣作業員間で合意を取る仕組みが必要である。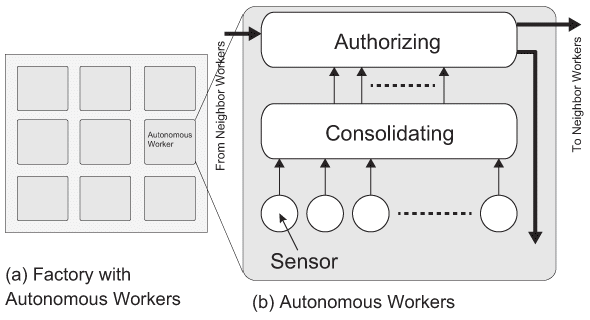 図1.1(c) IoT Based Factory Examples.: Distributed Management Based Factory.
図1.1(c) IoT Based Factory Examples.: Distributed Management Based Factory.
インターネットを使用する場合、特にセキュリティが重要になり、情報漏洩が発生することを前提にシステムを構築する必要がある。センサー近傍である程度の処理を行い、上位層へ個人情報を渡さないエッジ・コンピューティングに注目が集まっている。
1.4.2 トランザクション処理
ブロックチェーン(Block Chain)は2010年12月にSatoshi Nakamotoという仮名と思われる個人あるいは組織団体がインターネット上に公開した論文【50】に基づいた仮想通貨“BitCoin”の承認処理を行う仕組みであり、有形無形に関係なく全ての取り引き上の認証処理に応用可能な技術である。
Block Chainはビザンチン将軍問題(Byzantine Generals Problem【51】)上でも機能する承認処理技術である。ビザンチン将軍問題とは、複数の将軍が緩く繋がった中央集権の無いビザンチン帝国において、ある将軍が叛逆の可能性を含むことを踏まえた上で一つの帝国として合意形成するための方法の事である。つまり、商用システムでは“将軍間のやりとり”が“取り引き”であり、各“将軍”がシステムを構成する各計算機ノード上の取り引きを行う“利用者”に相当する。これらのノードが緩くネットワークで繋がった分散コンピューティング上での取り引き、あるいは手続き(Transactionと呼ぶ)の承認方法をいかに現実的な解として実現するかの問題といえる。
BitCoinによる商取り引きが機能するための必要十分条件は、
- 公開鍵方式等による取り引き参加者の認証が可能な事。
- 各取り引き参加者が取り引きを行うためのネットワークがあり、取り引き参加者間でそのネットワークを通して情報通信が可能な事。
の2点である。ここで、任意の計算機ノード上で取り引きを行う参加者が複数存在可能な事を踏まえて、計算機ノード単位ではなく参加者ごとに区別する事とする。想定する分散コンピューティング環境は以下の通りである。
- 不特定多数の参加者がネットワークを利用する。
- 計算機ノードは緩くネットワークに繋がっていて、常時接続を保証しない。
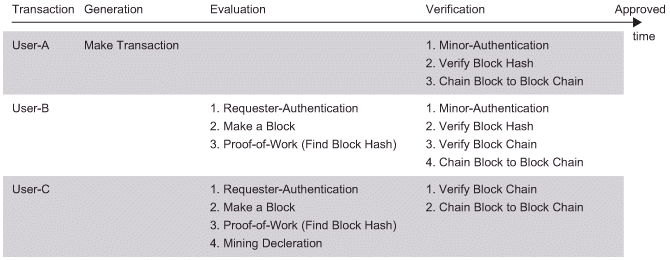
ここでの参加者は誤った情報を送受信したり、不正取り引きを試みようとする可能性がある。その環境下で合意形成をするための仕組みがBlock Chainである。全体としての合意形成は任意の取り引き参加者が不特定多数の参加者に対してTransactionの承認を要求し、他の参加者達はそのTransactionの評価・検証をした上で、要求している参加者のTransactionを各参加者が承認(Approve)する(図1.2参照)。
Block Chainの基本データ構造を図1.3(a)に示す。複数のTransactionをまとめて一つの処理単位であるBlockを構築し、承認はBlock単位で処理する。各Block内のTransactionは時系列の番号が付与され、Blockは時系列で繋がり、一つのBlock Chainを各参加者単位で構築・所有する。ここで、Block Chainにおいてその中に含むBlock数が分かるものとし、1以上のその値あるいは変数をNumBlocksとする。
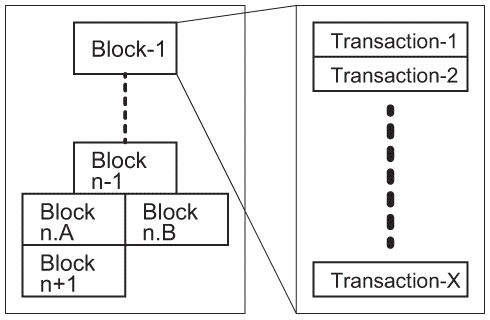
- 承認(Approving)とブロックのチェーン(Chaining)
認証処理は参加者認証サブシステム(取り引き要求者と検証参加者のどちらかあるいは両方の認証)とハッシュ関数で構成される取り引き認証サブシステムで構成され、Block Chainは後者の部分に該当する(図 1.3(b)参照)。参加者が認証され、かつハッシュ関数から得られるTransactionの認証鍵(これをHashValueと呼ぶことにする)と参加者間で共有(既知)の認証鍵(これをCOMMON_NUM_ZEROSと呼ぶこととする)が一致していれば取り引き要求は真である。取り引き要求が真の状態で、かつBlock Chain内のBlock情報を遡って照合作業を行い、不正がないことが確認されれば、各取り引き(各検証)参加者はその取り引き情報であるTransactionを含むBlockをBlock Chainの後端へ追加(Chain)する。 - Proof-of-Work
参加者は一定のTransactionが集まった時点でProof-of-Workと呼ぶ検証処理を行う。図1.3(b)とアルゴリズム1にProof-of-Workを示す。変数nonce値を変えながら、そのnonce値と最も最近のBlock(NumBlocks番目のBlock)の持つMerkleRoot値(アルゴリズム1ではNumBlocks番目のBlockのこのMerkleRoot値をGet_MerkleRoot関数から得るとする)を引数とするハッシュ関数(アルゴリズム1ではHashFunctionをその関数とする)を使用する。このハッシュ関数が返すハッシュ値(アルゴリズム1ではHashValue変数としている)の二進数表現において、その二進数値の最上位ビットから連続しているゼロ値の数NumZeros(アルゴリズム1ではHashValueを引数とするGet_NumZeros関数から得るとする)が参加者間で共有(既知)している公開鍵であるCOMMON_NUM_ZEROSと一致していれば、そのBlockは認証可能と判断する。このProof-of-Workの結果得られるnonce値とHashValueを他の参加者へ通知し、その参加者達は先に説明した認証処理を行い、そして照合処理を経てそのBlockは最終的に各参加者にて登録(chain)されて共有情報となる(Approve状態となる)。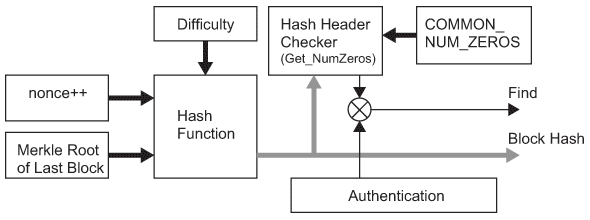 図1.3(b) Block Chain Core Architecture.: Proof-of-Work Architecture.RETRUN: Find, nonce, HashValue;Find = 0;MerkleRoot = Get_MerkleRoot(BlockChain, NumBlocks);for nonce = 0; nonce < 2size_of(unsigned int); nonce++ doHashValue = HashFunction(MerkleRoot, nonce);NumZeros = Get_NumZeros() HashValue);if NumZeros == COMMON_NUM_ZEROS thenFind = 1;return( Find, nonce, HashValue);endendreturn( Find, 0, 0);アルゴリズム1: Proof-of-Work
図1.3(b) Block Chain Core Architecture.: Proof-of-Work Architecture.RETRUN: Find, nonce, HashValue;Find = 0;MerkleRoot = Get_MerkleRoot(BlockChain, NumBlocks);for nonce = 0; nonce < 2size_of(unsigned int); nonce++ doHashValue = HashFunction(MerkleRoot, nonce);NumZeros = Get_NumZeros() HashValue);if NumZeros == COMMON_NUM_ZEROS thenFind = 1;return( Find, nonce, HashValue);endendreturn( Find, 0, 0);アルゴリズム1: Proof-of-Work - Block Chainの分岐
検証参加者は複数存在するので、複数の検証参加者から同じ値を持つProof-of-Work検証結果の同時受信が発生し得る。参加者が複数の正当な通知を同時に受け取った場合、それらの正当な通知を行っている複数の追加候補のBlockを同じレベル(同じ時点でのBlock候補)として、Block Chainへ追加する(図1.3(a)参照)。Block ChainはBlockの時系列性を使用してるので、各参加者が次のBlockに対するProof-of-Workを行う際に最も最近の複数存在し得る追加候補からBlock一つを選択する必要がある。従って、複数回の検証処理を経て各参加者はBlock Chainの分岐点から異なる長さを持つBlock列を複数持ち、Block chainは複数の分岐により木構造のデータ構造になる(図1.3(a)参照)。任意の分岐点において有効なBlock列を持つ分岐先を判定する条件は、その分岐点からのBlock列が最も長い事である。
時系列で繋がったBlockで構成されたBlock Chainというデータ構造とハッシュ関数を使用することで、取り引き情報の改ざん行為を困難にしている。これは過去の取り引き履歴で構成されるBlock Chainを一連のハッシュ値を破壊しないように改ざんする必要があるからであり、改ざんには計算処理能力を必要とする。
BitCoinで提案されたBlock Chainの仕組みを持つ仮想取り引きシステム上では、コスト的に割に合わない計算処理を行うよりも、公正な取り引きに参加した方が収益を得やすい合理性を持つ。そして最初に説明した様に、有形無形に関係なく全て(Everything)の取り引き上の認証処理に応用可能な技術である。
機械学習は特定環境下の入力データに対して利用者にとって関心のある認識等を行うデータ処理系であり、ブロックチェーンはその様なデータ処理を誤りなく行うための手続き(Transaction)処理である。Transactionは各データ処理の間に介在し、この2つの処理系を2ステージパイプライン処理として構成できる。Transaction処理であれば、ブロックチェーンは何にでも適用できる。例えば、Industry4.0において人とロボットとの干渉問題に対して適用したり、LSI(SoC; System-on-Chip)上のハードウェアIP(Interectual Property)といったモジュール間の共有データのやり取り、メニーコアプロセッサにおけるキャッシュメモリのコヒーレンス問題等、遅延が非同期であり多数の変数を共有したいノードがチップ上にある分散コンピューティングの場合に適用可能である。また、テストベクトルをチップに流してその履歴をBlock Chainで取ることでハードウェアIPの不良検出にも使用できる。
■
次回は、「第2章 従来のアーキテクチャ、2.1 ハードウェア実装の現実」を転載します。
【参考文献】
- 【49】 川野 俊充. ドイツが描く第4次産業革命「インダストリー4.0」とは?【前編】(1/4). http://monoist.atmarkit.co.jp/mn/articles/1404/04/news014.html, 2016.
- 【50】 Satoshi Nakamoto. Bitcoin: A Peer-to-Peer Electronic Cash System. https://bitcoin.org/bitcoin.pdf, December 2010.
- 【51】 M. Pease, R. Shostak, and L. Lamport. Reaching Agreement in the Presence of Faults. J. ACM, 27(2):228-234, April 1980.
※以下では、本稿の前後を合わせて5回分(第1回~第5回)のみ表示しています。
連載の全タイトルを参照するには、[この記事の連載 INDEX]を参照してください。
1. 機械学習の定義と応用範囲、認知されるキッカケとなった出来事
機械学習はいまなぜ広く認知され注目されているのか。知っておきたい代表的な出来事を紹介。また、機械学習とは何かを定義し、その適用範囲を分類する。
2. 機械学習における学習方法と性能評価の基礎知識
機械学習の基礎知識として、学習用データセットの準備と加工、学習方法(勾配降下法/誤差逆伝播法)やその分類(教師あり学習/教師なし学習/強化学習)、性能評価と検証について概説する。
3. 【現在、表示中】≫ 第4次産業革命とは? 機械学習とブロックチェーンの役割
機械学習の新技術活用は第4次産業革命と呼ばれるが、その意味を説明。さらに、機械学習がデータ処理系であれば手続き処理系に相当するブロックチェーンについても概説する。
4. マイクロプロセッサからGPU/FPGAの利用へ ― 機械学習ハードウェア実装に関する時代変遷
計算機システムのハードウェア実装では、従来の主要要素であるマイクロプロセッサの性能向上が停滞してきたことから、GPUやFPGAが採用されるように時代が変遷してきた。その内容について概説する。
5. 機械学習ハードウェアの基礎知識: 特定用途向け集積回路「ASIC」
特定アプリケーションに特化した回路を集積する方法であるASICについて概説。アプリケーションを表現するアルゴリズムのソフトウェア実装とASIC実装を比較しながらASIC実装の特徴と制約を説明する。